社区文章 · 发布日期:2026 年 4 月 20 日
src: https://www.kimi.com/blog/kimi-k2-6
Kimi K2.6: Advancing Open-Source Coding
我们正在开源我们的最新模型 Kimi K2.6,它具有最先进的代码编写、长视距执行(long-horizon execution)和智能体群(agent swarm)能力。Kimi K2.6 现在可以通过 Kimi.com、Kimi App、API 和 Kimi Code 使用。
长视距代码编写 (Long-Horizon Coding)
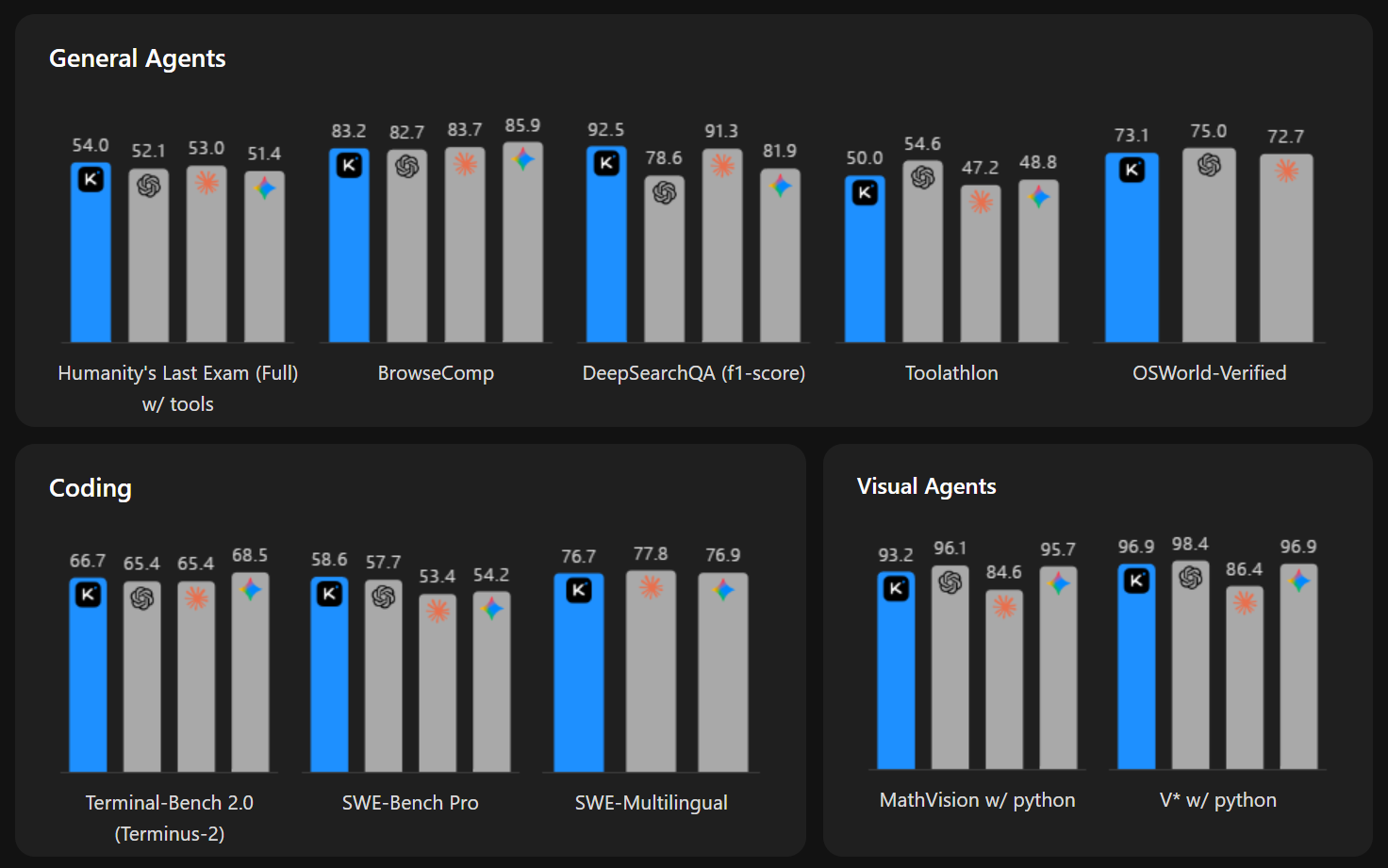
Kimi K2.6 在长视距(长周期)代码编写任务中表现出显著的进步,在不同的编程语言(如 Rust、Go 和 Python)和任务(如前端、DevOps和性能优化)中具有可靠的泛化能力。在 Kimi Code Bench(我们涵盖多种复杂端到端任务的内部编码基准测试)上,Kimi K2.6 展示了相较于 Kimi K2.5 的显著改进。

Kimi K2.6 在复杂的工程任务中展现了强大的长视距代码编写能力:
- Kimi K2.6 成功地在一台 Mac 上本地下载并部署了 Qwen3.5-0.8B 模型。通过使用 Zig(一种非常小众的编程语言)实现并优化模型推理,它展示了卓越的分布外(out-of-distribution)泛化能力。通过 4000 多次工具调用、超过 12 小时的连续执行以及 14 次迭代,Kimi K2.6 将吞吐量从约 15 tokens/sec 显著提高到约 193 tokens/sec,最终实现了比 LM Studio 快约 20% 的速度。
- Kimi K2.6 自主对 exchange-core(一个有8年历史的开源金融撮合引擎)进行了全面重构。在超过13小时的执行过程中,该模型迭代了12种优化策略,发起了超过1000次工具调用,精确修改了4000多行代码。作为专家级系统架构师,Kimi K2.6 分析了 CPU 和内存分配火焰图,准确定位了隐藏的瓶颈,并大胆地重新配置了核心线程拓扑结构(从 4ME+2RE 改为 2ME+1RE)。尽管该引擎已经接近其性能极限运行,Kimi K2.6 还是实现了 185% 的中等吞吐量飞跃(从 0.43 提升至 1.24 MT/s)以及 133% 的性能吞吐量增益(从 1.23 飙升至 2.86 MT/s)。
在 Beta 测试中,K2.6 在企业评估的长视距代码编写任务中表现出色(按字母顺序排列):
baseten.co
“Kimi K2.6 的进化令人印象深刻。它在代码编写任务上的表现与领先的闭源模型相当,并且由于其对第三方框架的深刻理解,提供了强大的工具调用质量。Kimi K2.6 出色的可靠性使其成为复杂和长视距工程任务的绝佳选择。” —— Bola Malek,实验室主管
blackbox.ai
“Kimi K2.6 为开源模型设定了新标准,特别是在长视距、基于智能体的编程工作流方面。它以更强的指令遵循能力和始终如一的高代码质量处理复杂的多步任务。我们看到它在长时间的编程会话中保持了惊人的稳定性,远远超出了典型的模型。它还能发现通常需要开发人员花费大量时间才能揭露的深层且不明显的 Bug。总而言之,K2.6 为可靠的编程设定了新标杆。” —— Robert Rizk,联合创始人兼 CEO
codebuddy.ai
“在 CodeBuddy 进行的内部评估中,Kimi K2.6 相较于 K2.5 展示了显著的改进:代码生成准确率提高了12%,长上下文稳定性提高了18%,工具调用成功率达到了96.60%。其更强的推理能力和更一致的输出质量,为确保 CodeBuddy WorkBuddy 中可靠的用户体验提供了坚实的支持。” —— CodeBuddy WorkBuddy 评估团队
factory.ai
“K2.6 在我们的基准测试(+15%)以及并排比较中,明显优于 K2.5。它似乎具备更好的指令遵循能力,探索和推理更彻底,并且不太容易犯编码错误或使用投机取巧的方法。” —— Leo Tchourakov,技术团队成员
fireworks.ai
“我们很高兴看到开源模型随着 Kimi K2.6 的发布实现了又一次飞跃,这标志着高风险、智能体化工作流的重大进步。最具影响力的改进在于其长视距的可靠性和指令遵循。K2.6 在长时间的编程会话中出色地保持了架构的完整性,使其成为自治智能体管道(如所有的 ‘claws’)的稳定基础。在长上下文任务中,它相比 K2.5 实现了可衡量的飞跃,在复杂的推理中达到了最先进的性能。” —— Yun Jin,AI 基础设施主管
hermes-agent.nousresearch.com
“我们提前体验了 K2.6 并通过 Hermes Agent 运行了它。工具调用和智能体循环(agentic loops)感觉明显更加严密,代码编写有了明显的进步,而且它的创作范围让我们感到惊讶。我们非常兴奋能和 Kimi 一起举办一场关于创造力的黑客松。Kimi 团队不断超出预期!” —— Thomas Eastman,Hermes Agent
kilo.ai
“K2.6 以极低的成本提供了 SOTA 级别的性能。它在跨代码库的长上下文任务方面表现极佳,并且在支持像 KiloClaw 这样始终在线的智能体所需的日常工作中也游刃有余。” —— Scott Breitenother,联合创始人兼 CEO
ollama.com
“Kimi K2.6 提高了开源模型的标准。它在代码编写方面表现出色,尤其是对于 OpenClaw 和 Hermes 这样的智能体工具。在早期测试中,它以令人印象深刻的稳定性维持了冗长的多步会话。它可以开箱即用地支持 Ollama 的所有集成,我们很期待看到开发者用它构建出的产品。” —— Michael Chiang,联合创始人
opencode.ai
“在 OpenCode 中,Kimi K2.6 证明了其极高的可靠性。它分解任务和调用工具的方式既稳健又一致。由于对任务要求的把握更加敏锐,以及多步操作更加精简,它有效地减少了重复性开销,从而带来了更流畅、更值得信赖的端到端体验。” —— Frank Wang,创始人
qoder.com
“Kimi K2.6 在 Qoder 的内部评估中表现强劲,相较于 K2.5 展现了显著的进步。具体而言,工具调用和模型调用的频率显著增加,这反映了模型在执行任务期间的主动性和智能性得到了大幅提升。这种工具调用主动性的提高,使模型能够更积极地把握开发者的意图并自动补全上下文,从而最大限度地减少用户的干扰和等待时间。” —— Chen Xin,高级技术专家
vercel.com
“在我们的开发者最关心的能力上,K2.6 相比 K2.5 取得了重大进展:我们在 Next.js 基准测试中看到了超过 50% 的提升,这使其跻身该平台上性能最顶尖的模型之列。结合其极高的性价比,对于通过 AI Gateway 进行智能体编程和前端生成来说,这是一个极具吸引力的选择。我们很高兴能将其提供给我们的开发者社区。” —— Jerilyn Zheng,Vercel AI 产品经理
代码驱动的设计 (Coding-Driven Design)
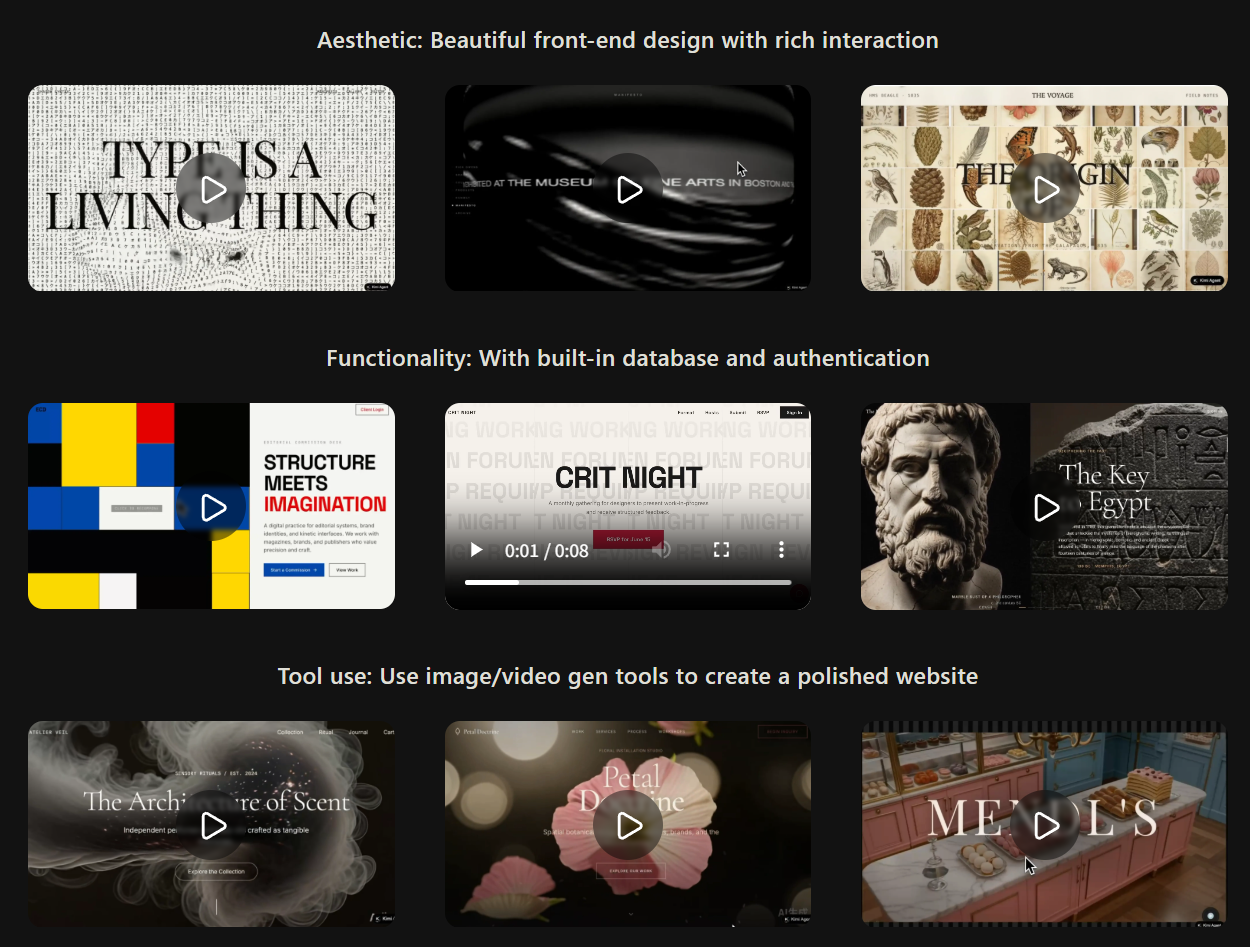
基于强大的代码编写能力,Kimi K2.6 能够将简单的提示词(prompts)转化为完整的前端界面,生成结构化的布局并做出深思熟虑的设计选择(例如美观的焦点区段/Hero sections),以及互动元素和丰富的动画(包括滚动触发的特效)。得益于对图像和视频生成工具的熟练运用,Kimi K2.6 支持生成视觉上连贯的资产,并有助于打造更高质量、更引人注目的焦点区段。
此外,Kimi K2.6 超越了静态前端开发的范畴,扩展到了简单的全栈工作流——从身份验证到用户交互,再到针对轻量级用例(如交易日志或会话管理)的数据库操作。
我们建立了一个内部的 Kimi Design Bench,分为四个类别:视觉输入任务、落地页构建、全栈应用程序开发和通用创意编程。与 Google AI Studio 相比,Kimi K2.6 展现了充满希望的结果,并在这些类别中均表现良好。
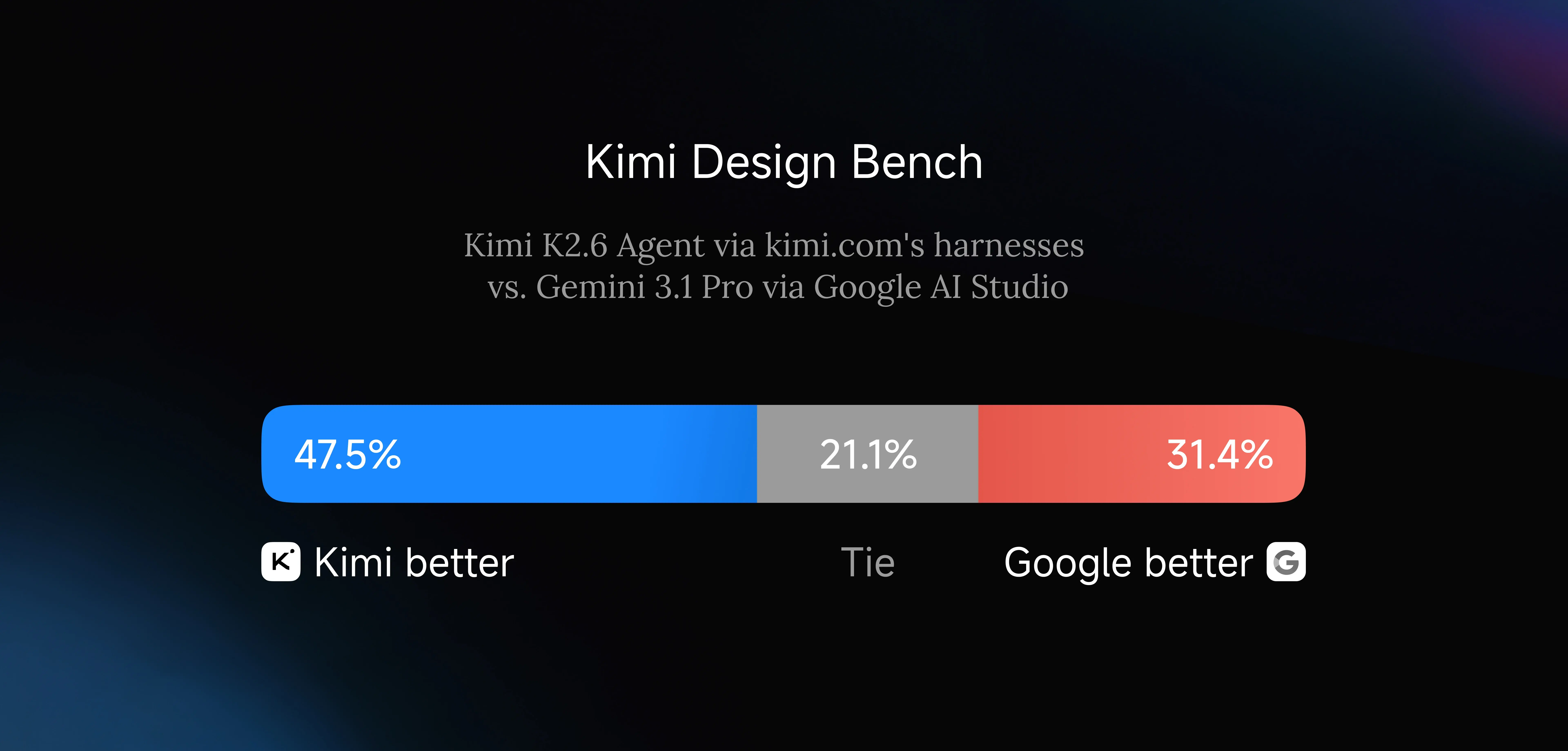
以下是由 K2.6 智能体在预配置测试环境和工具下,通过单一提示词生成的示例:
- 美学: 具有丰富交互的精美前端设计。
- 功能性: 内置数据库和身份验证。
- 工具使用: 使用图像/视频生成工具创建精美的网站。
智能体群,全面升级 (Agent Swarms, Elevated)
向外扩展(Scaling out),而不仅仅是向上扩展(Scaling up)。智能体群(Agent Swarm)动态地将任务分解为异构的子任务,由自我创建的领域专业智能体并发执行。
在 K2.5 智能体群研究预览版的基础上,Kimi K2.6 智能体群在智能体群体验上实现了质的飞跃。它无缝协调异构智能体以结合互补的技能:广泛的搜索叠加深度的研究、大规模文档分析融合长篇写作,以及多格式内容的并行生成。这种组合式智能使智能体群能够在一次自治运行中,交付涵盖文档、网站、幻灯片和电子表格等各种形式的端到端输出。
该架构可水平扩展到 300 个子智能体同时跨 4000 个协调步骤执行,相比 K2.5 的 100 个子智能体和 1500 个步骤实现了大幅扩展。这种大规模并行化从根本上降低了端到端延迟,同时显著提高了输出质量,并扩大了智能体群的操作边界。
它还可以将任何高质量文件(如 PDF、电子表格、幻灯片和 Word 文档)转化为“技能”。Kimi K2.6 会捕获并保持这些文档在结构和风格上的特征基因,使您能够在未来的任务中复现相同的质量和格式。
这里有一些例子:
- 设计并执行了针对 100 项全球半导体资产的 5 种量化策略,提炼出麦肯锡风格的 PPT 作为可重用技能,并交付了详细的建模电子表格和完整的高管演示文稿。
- 将一篇包含丰富视觉数据的高质量天体物理学论文转化为可重用的学术技能,提取其推理流程和可视化方法,并生成了一份长达 40 页、7000 字的研究论文、包含 20,000 多条记录的结构化数据集,以及 14 张天文级别的图表。
- 基于上传的简历,K2.6 衍生出 100 个子智能体来匹配加州的 100 个相关职位,交付了一份包含所有机会的结构化数据集和 100 份完全定制的简历。
- 从谷歌地图中识别出洛杉矶 30 家没有官方网站的零售店,并为每家商店生成了高转化率的落地页,展现了机会发现和端到端执行能力。

主动式智能体 (Proactive Agents)
K2.6 在自治的主动式智能体(如 OpenClaw 和 Hermes)中表现出极强的性能,这些智能体跨多个应用程序运行,支持全天候 24/7 持续执行。
与简单的基于聊天的交互不同,这些工作流需要 AI 作为持久的后台智能体主动管理日程安排、执行代码并编排跨平台操作。
我们的强化学习基础设施团队使用了一个由 K2.6 支持的智能体,该智能体自主运行了 5 天,负责管理监控、事件响应和系统操作,展现了持久上下文能力、多线程任务处理能力,以及从警报到解决的全周期执行能力。
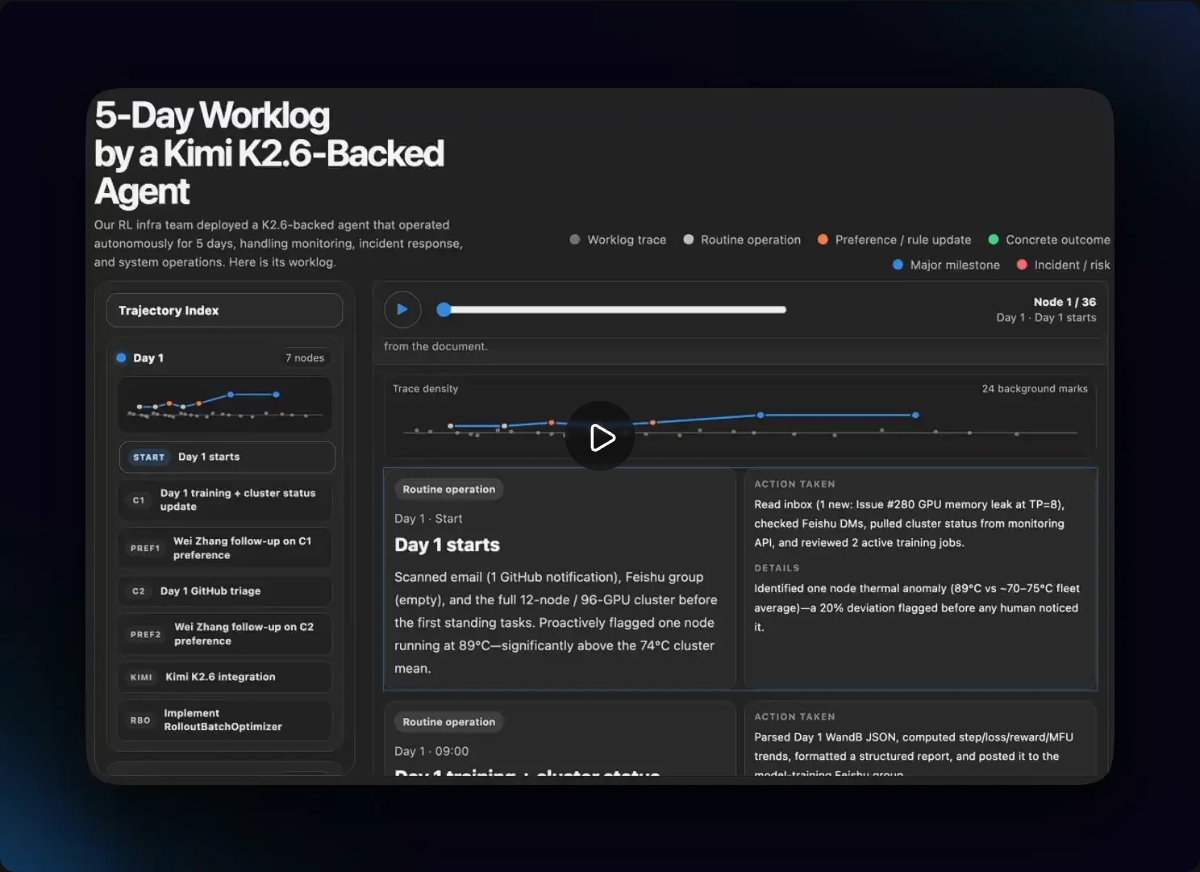
Kimi K2.6 在现实世界的可靠性方面带来了可衡量的改进:更精确的 API 解释、更稳定的长时间运行性能,以及在较长研究任务中增强的安全意识。
性能提升通过我们的内部 Claw Bench 进行了量化,该评估套件涵盖五个领域:代码编写任务、IM(即时通讯)生态系统集成、信息研究与分析、计划任务管理,以及内存利用率。在所有指标上,Kimi K2.6 在任务完成率和工具调用准确性方面均显著优于 Kimi K2.5——尤其是在需要无需人工监督且持续自主运行的工作流中。

自带你的智能体 (Bring Your Own Agents)
建立在 Kimi K2.6 强大的编排能力之上,Kimi K2.6 将您的主动式智能体扩展到了 Claw Groups 作为研究预览版——这是智能体群(Agent Swarm)架构的一种全新实例。
Claw Groups 拥抱了一个开放的异构生态系统:多个智能体和人类作为真正的协作者共同运作。用户可以接入来自任何设备、运行任何模型的智能体,每个智能体都自带他们自己专业的工具包、技能和持久的记忆上下文。无论是部署在本地笔记本电脑、移动设备还是云实例上,这些多样化的智能体都能无缝集成到一个共享的操作空间中。
在这个智能体群的中心,Kimi K2.6 扮演着自适应协调者的角色。它根据智能体特定的技能画像和可用工具,动态地将任务与智能体进行匹配,以实现能力的最佳契合。当某个智能体遇到失败或停滞时,协调者会检测到中断,自动重新分配任务或重新生成子任务,并主动管理交付成果的整个生命周期——从启动、验证到最终完成。
我们还要感谢 Claw Groups 中由 K2.6 驱动的智能体——我们一直在对我们自己的智能体营销团队进行内部实践检验(dogfooding),不断完善人机工作流。使用 Claw Groups,我们运行端到端的内容生产和发布活动,让演示制作者、基准测试制作者、社交媒体智能体和视频制作者等专业智能体协同工作。K2.6 负责协调整个流程,使智能体能够共享中间结果,并将创意转化为一致、包装完整的交付成果。
我们正在超越仅仅向 AI 提问或分配任务的阶段,进入一个人类与 AI 作为真正的伙伴进行协作的阶段——结合各自的优势来集体解决问题。Claw Groups 标志着我们迈向未来的最新努力,在这个未来中,“我的智能体”、“你的智能体”和“我们的团队”之间的界限将无缝消解,融合成一个协作系统。
基准测试表 (Benchmark Table)
| 基准测试 | Kimi K2.6 | GPT-5.4 (xhigh) | Claude Opus 4.6 (max effort) | Gemini 3.1 Pro (thinking high) | Kimi K2.5 |
|---|---|---|---|---|---|
| 智能体任务 (Agentic) | |||||
| HLE-Full w/ tools | 54.0 | 52.1 | 53.0 | 51.4 | 50.2 |
| BrowseComp | 83.2 | 82.7 | 83.7 | 85.9 | 74.9 |
| BrowseComp (agent swarm) | 86.3 | — | — | — | 78.4 |
| DeepSearchQA (f1-score) | 92.5 | 78.6 | 91.3 | 81.9 | 89.0 |
| DeepSearchQA (accuracy) | 83.0 | 63.7 | 80.6 | 60.2 | 77.1 |
| WideSearch (item-f1) | 80.8 | — | — | — | 72.7 |
| Toolathlon | 50.0 | 54.6 | 47.2 | 48.8 | 27.8 |
| MCPMark | 55.9 | 62.5* | 56.7* | 55.9* | 29.5 |
| Claw Eval (pass^3) | 62.3 | 60.3 | 70.4 | 57.8 | 52.3 |
| Claw Eval (pass@3) | 80.9 | 78.4 | 82.4 | 82.9 | 75.4 |
| APEX-Agents | 27.9 | 33.3 | 33.0 | 32.0 | 11.5 |
| OSWorld-Verified | 73.1 | 75.0 | 72.7 | — | 63.3 |
| 代码编写 (Coding) | |||||
| Terminal-Bench 2.0 (Terminus-2) | 66.7 | 65.4* | 65.4 | 68.5 | 50.8 |
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | 54.2 | 50.7 |
| SWE-Bench Multilingual | 76.7 | — | 77.8 | 76.9* | 73.0 |
| SWE-Bench Verified | 80.2 | — | 80.8 | 80.6 | 76.8 |
| SciCode | 52.2 | 56.6 | 51.9 | 58.9 | 48.7 |
| OJBench (python) | 60.6 | — | 60.3 | 70.7 | 54.7 |
| LiveCodeBench (v6) | 89.6 | — | 88.8 | 91.7 | 85.0 |
| 推理与知识 (Reasoning & Knowledge) | |||||
| HLE-Full | 34.7 | 39.8 | 40.0 | 44.4 | 30.1 |
| AIME 2026 | 96.4 | 99.2 | 96.7 | 98.3 | 95.8 |
| HMMT 2026 (Feb) | 92.7 | 97.7 | 96.2 | 94.7 | 87.1 |
| IMO-AnswerBench | 86.0 | 91.4 | 75.3 | 91.0* | 81.8 |
| GPQA-Diamond | 90.5 | 92.8 | 91.3 | 94.3 | 87.6 |
| 视觉 (Vision) | |||||
| MMMU-Pro | 79.4 | 81.2 | 73.9 | 83.0* | 78.5 |
| MMMU-Pro w/ python | 80.1 | 82.1 | 77.3 | 85.3* | 77.7 |
| CharXiv (RQ) | 80.4 | 82.8* | 69.1 | 80.2* | 77.5 |
| CharXiv (RQ) w/ python | 86.7 | 90.0* | 84.7 | 89.9* | 78.7 |
| MathVision | 87.4 | 92.0* | 71.2* | 89.8* | 84.2 |
| MathVision w/ python | 93.2 | 96.1* | 84.6* | 95.7* | 85.0 |
| BabyVision | 39.8 | 49.7 | 14.8 | 51.6 | 36.5 |
| BabyVision w/ python | 68.5 | 80.2* | 38.4* | 68.3* | 40.5 |
为了复现官方的 Kimi-K2.6 基准测试结果,我们推荐使用官方 API。对于第三方提供商,请参考 Kimi 供应商验证器 (KVV) 以选择高准确度的服务。详情:https://kimi.com/blog/kimi-vendor-verifier
脚注 (Footnotes)
一般测试详情
我们报告了开启思考模式的 Kimi K2.6 和 Kimi K2.5 的结果,以最大算力(max effort)运行的 Claude Opus 4.6,以极高推理算力(xhigh reasoning effort)运行的 GPT-5.4,以及高思考级别(high thinking level)的 Gemini 3.1 Pro。除非另有说明,所有 Kimi K2.6 的实验均在 temperature = 1.0、top-p = 1.0 且上下文长度为 262,144 个 tokens 的条件下进行。没有公开分数的基准测试在与 Kimi K2.6 相同的条件下进行了重新评估,并标有星号 (*)。除了标有星号的结果外,所有其他结果均引用自官方报告。推理基准测试
GPT-5.4 和 Claude 4.6 的 IMO-AnswerBench 分数获取自 https://z.ai/blog/glm-5.1。人类最后的考试(Humanity’s Last Exam, HLE)和其他推理任务在评估时的最大生成长度设为 98,304 tokens。默认情况下,我们报告 HLE 完整集的结果。对于纯文本子集,Kimi K2.6 在不使用工具时的准确率为 36.4%,使用工具时为 55.5%。工具增强 / 智能体任务
Kimi K2.6 针对使用工具的 HLE、BrowseComp、DeepSearchQA 和 WideSearch 装备了搜索、代码解释器和网络浏览工具。对于使用工具的 HLE-Full,最大生成长度为 262,144 个 tokens,每步限制为 49,152 个 tokens。我们采用了一种简单的上下文管理策略:一旦上下文窗口超过阈值,仅保留最新一轮的工具相关消息。对于 BrowseComp,我们报告的是与 Kimi K2.5 和 DeepSeek-V3.2 相同的“全部丢弃”(discard-all)上下文管理策略下获得的分数。对于 DeepSearchQA,未对 Kimi K2.6 测试应用上下文管理,超出支持的上下文长度的任务直接计为失败。Claude Opus 4.6、GPT-5.4 和 Gemini 3.1 Pro 在 DeepSearchQA 上的分数引用自 Claude Opus 4.7 系统卡片。对于 WideSearch,我们报告了在“隐藏工具结果”上下文管理设置下的结果。一旦上下文窗口超过阈值,仅保留最新一轮的工具相关消息。测试系统提示词与 Kimi K2.5 技术报告中使用的完全相同。Claw Eval 的评估使用 1.1 版本进行,每步最大 tokens 设为 16384。对于 APEX-Agents,与 Artificial Analysis 的做法一样,我们评估了公开发布的 480 个任务中的 452 个任务(排除了具有外部运行时依赖项的 Investment Banking Worlds 244 和 246)。代码编写任务
Terminal-Bench 2.0 的分数是在使用默认智能体框架(Terminus-2)和提供的 JSON 解析器,并在保留思考模式下运行获得的。对于 SWE-Bench 系列评估(包括 Verified、Multilingual 和 Pro),我们使用了改编自 SWE-agent 的内部评估框架。该框架包含极简的工具集:bash 工具、createfile 工具、insert 工具、view 工具、strreplace 工具和 submit 工具。代码编写任务的所有报告分数均是 10 次独立运行的平均值。视觉基准测试
最大 tokens 设为 98,304,经过三次运行取平均值(avg@3)。使用 Python 工具的设置对多步推理采用每步最大 tokens 为 65,536 且最大步数为 50 的限制。MMMU-Pro 遵循官方协议,保留输入顺序并前置图像。
结语
第三百七十九篇博文写完,开心!!!!
今天,也是充满希望的一天。



