社区文章 · 发布日期:2026 年 3 月 18 日
src: https://www.minimax.io/news/minimax-m27-en
MiniMax M2.7: Early Echoes of Self-Evolution
在我们首次发布M2系列模型后的几个月里,我们收到了大量来自热心用户和开发者的反馈与建议,这驱使我们进一步加速模型迭代的效率。随着人类生产力已经被充分释放,自然的下一步便是启动模型与组织的自我进化。M2.7是我们首个深度参与其自身进化的模型。
M2.7能够构建复杂的智能体线束(agent harnesses)并完成极其精细的生产力任务,这得益于其智能体团队(Agent Teams)、复杂技能(complex Skills)以及动态工具搜索等能力。例如,在开发M2.7时,我们让模型更新其自身的记忆,并在其线束中构建数十项复杂的技能,以辅助强化学习实验。我们进一步让模型根据实验结果改进其学习过程和线束。这一过程开启了模型自我进化的循环。
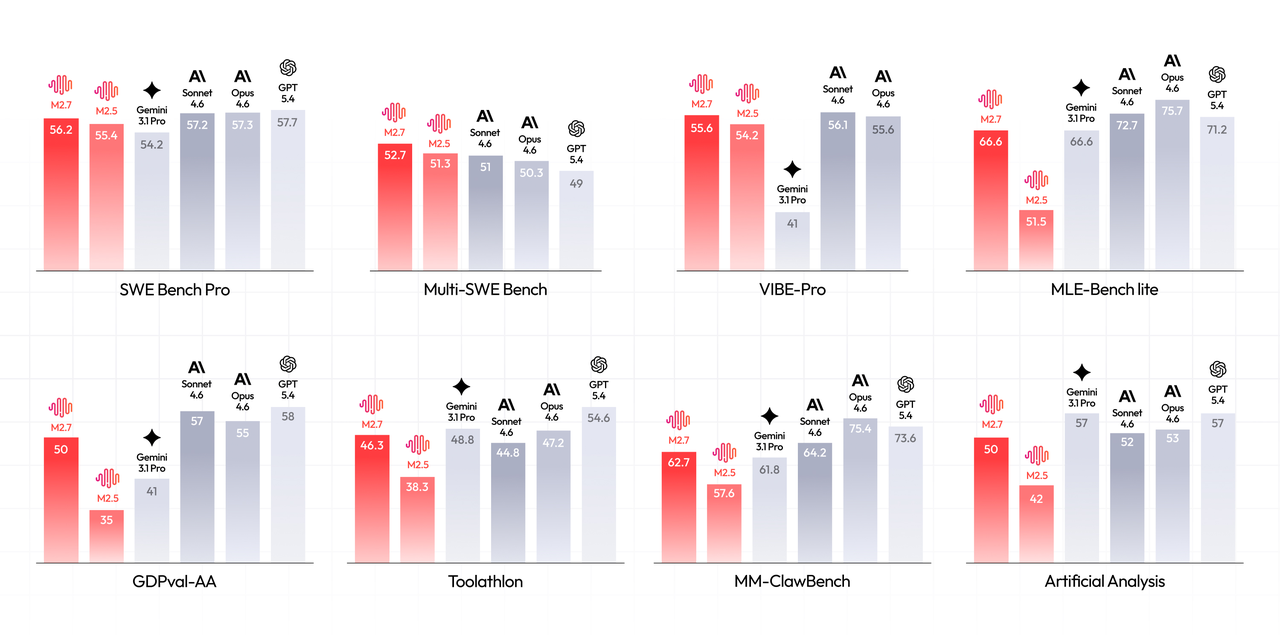
M2.7在现实世界的软件工程中表现卓越,包括端到端的全项目交付、日志分析、Bug排查、代码安全、机器学习等。在SWE-Pro基准测试中,M2.7得分为56.22%,几乎逼近Opus的最高水平。这种能力同样延伸到了端到端全项目交付场景(VIBE-Pro 55.6%),以及对复杂工程系统具备深刻理解的Terminal Bench 2(57.0%)。
我们还增强了该模型在专业办公软件领域各项专业知识与任务交付的能力。 它在GDPval-AA上的ELO评分为1495,是开源模型中最高的。M2.7在Office套件(Excel、PPT和Word)的复杂编辑能力上展现出显著提升,能够更好地处理多轮修改和高保真编辑。M2.7具备与复杂环境交互的能力:在处理40多项复杂技能(每项技能均超过2000 tokens)时,它保持了97%的技能遵循率。
M2.7展现了出色的人设一致性和情商,为产品创新开辟了更大的空间。
基于上述能力,M2.7也正在大幅加速我们自身向AI原生组织进化的步伐。
构建用于模型自我进化的智能体
我们首先分享一个能让M2系列模型实现自我进化的内部工作流。这一工作流也起到了探索模型智能体能力边界的作用。
现代智能体线束结合了复杂技能、记忆及其他外部模块,以帮助提高其对各种工作区环境的适应能力。在MiniMax,我们的智能体日常需要面对跨越多个部门、极其复杂且多样化的工作环境。因此,为了提高我们的智能体在这些异构环境中的鲁棒性,我们安排了一个内部版本的M2.7去构建一个研究型智能体线束,该线束能与不同的研究项目组进行互动和协作。该线束支持数据流水线、训练环境、基础设施、跨团队协作以及持久化记忆——使得研究人员能够驱动它交付更好的模型。这个研究型智能体线束在研究人员设定的指导下,推动了产生下一代模型的迭代周期。
一个典型的工作流存在于我们强化学习(RL)团队的日常中。研究人员首先与智能体讨论一个实验想法,智能体会协助进行文献综述、追踪预设的实验规范、搭建数据和其他工件的流水线,并启动实验。在实验期间,智能体会监控并剖析实验进度,自动触发日志读取、调试、指标分析、代码修复、合并请求(merge requests)以及冒烟测试,识别并配置那些细微却关键的变更。在此之前,这可能需要来自不同团队的多名人类研究人员协同合作,但现在人类研究人员只需进行关键决策和讨论即可。这加速了问题的发现和实验过程,从而更快地交付模型。在这里,M2.7能够处理30%-50%的工作流。
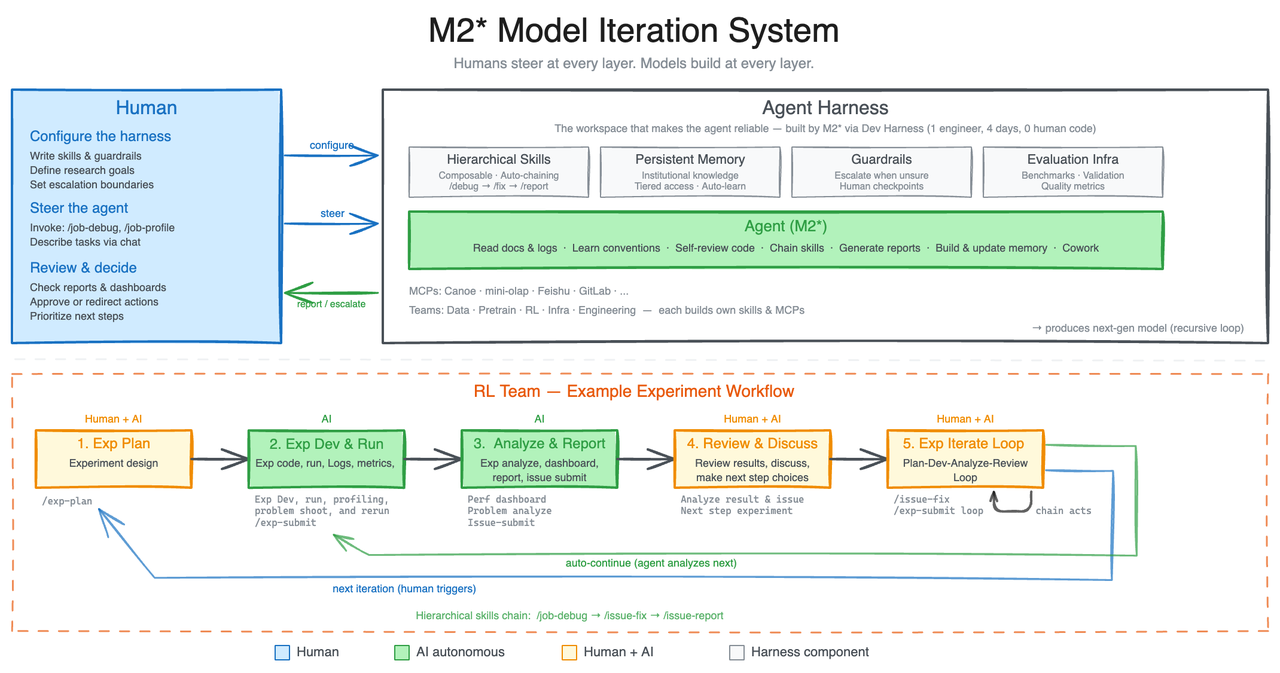
在迭代过程中,我们意识到模型递归演进其自身线束的能力同样至关重要。我们的内部线束会自动收集反馈,为内部任务构建评估集,并以此为基础持续迭代其自身的架构、技能/MCP实现和记忆机制,以更好、更高效地完成任务。
例如,我们曾让M2.7在一个内部脚手架上优化某个模型的编程性能。M2.7完全自主运行,执行了超过100轮的迭代循环:“分析失败轨迹 → 规划变更 → 修改脚手架代码 → 运行评估 → 对比结果 → 决定保留或回退变更”。在这个过程中,M2.7为模型发现了有效的优化方案:系统地搜索采样参数的最佳组合(如温度、频率惩罚和存在惩罚);为模型设计更具体的工作流指南(例如,在修复后自动在其他文件中搜索相同的bug模式);并在脚手架的智能体循环中添加循环检测等其他优化。最终,这使得内部评估集的性能提升了30%。
我们相信,未来的AI自我进化将逐渐向完全自治过渡,在无需人类参与的情况下协调数据构建、模型训练、推理架构、评估等各个阶段。
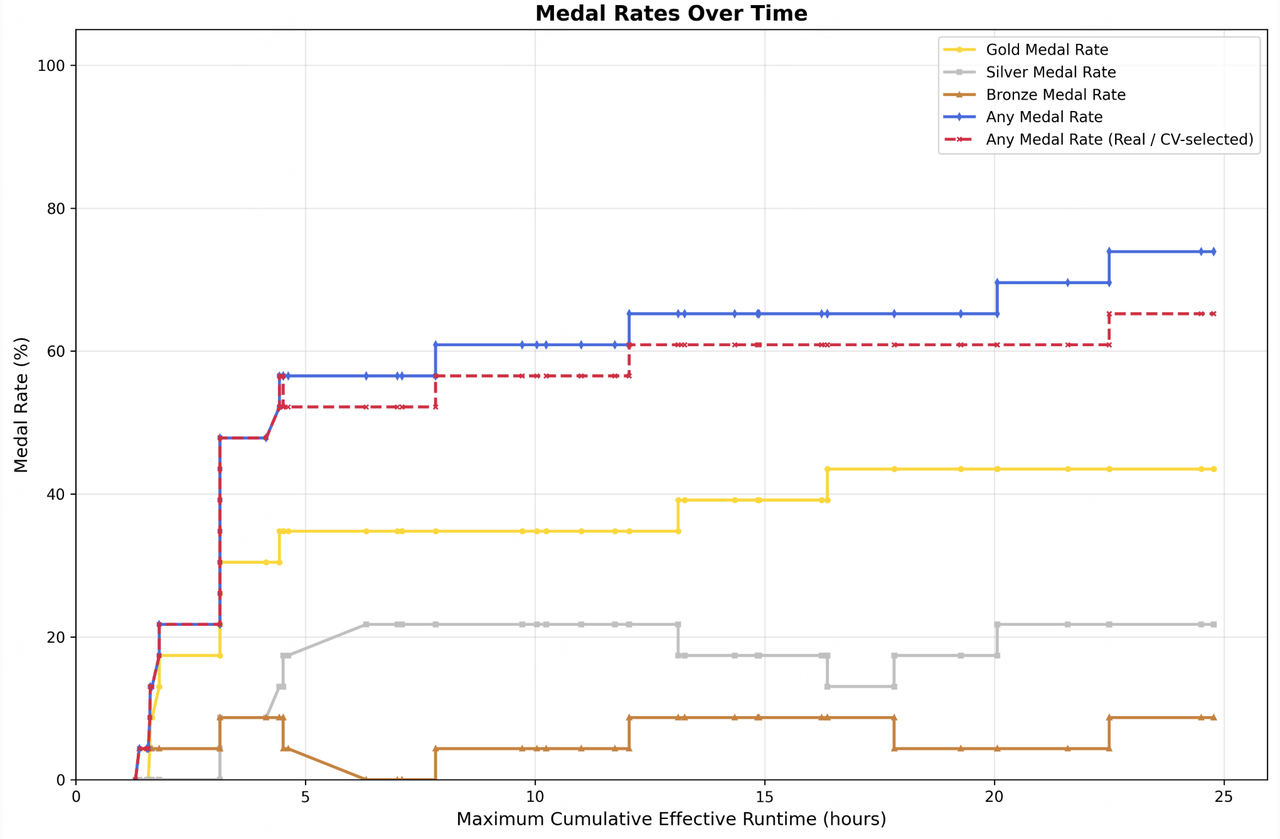
为此,我们在低资源场景中进行了初步的探索性测试。我们让M2.7参与了OpenAI开源的MLE Bench Lite级别的22项机器学习比赛。这些比赛可以在单张A30 GPU上运行,但它们几乎涵盖了机器学习工作流的所有阶段。
我们设计并实现了一个简单的线束来引导智能体进行自主优化。其核心模块包含三个部分:短期记忆、自我反馈和自我优化。具体而言,在每个迭代轮次之后,智能体会生成一个短期记忆的Markdown文件,同时对当前轮次的结果进行自我批判,从而为下一轮提供潜在的优化方向。然后,下一轮再根据之前所有轮次的记忆和自我反馈链条进行进一步的自我优化。我们总共进行了三次试验,每次试验均给予24小时的迭代进化时间。从下图中可以看出,随着时间的推移,由M2.7训练的机器学习模型持续获得了更高的奖牌率。最终,最好的一次运行斩获了9枚金牌、5枚银牌和1枚铜牌。三次运行的平均奖牌率为66.6%,这一成绩仅次于Opus-4.6(75.7%)和GPT-5.4(71.2%),与Gemini-3.1(66.6%)并列。
专业软件工程
在软件工程任务中,M2.7更深度地探索了现实世界的编程能力,包括用于Bug狩猎的日志分析、代码重构、代码安全、机器学习、Android开发等。
以一个常见的生产场景为例:生产环境中的线上调试。这不仅需要代码生成,还需要强大的综合推理能力。当面临生产环境的警报时,M2.7能够将监控指标与部署时间线关联起来进行因果推理,对Trace采样进行统计分析并提出精准假设,主动连接数据库以验证根本原因,精准定位代码仓库中缺失的索引迁移文件,甚至具备“先用非阻塞方式创建索引止血,再提交合并请求”的意识。从可观测性分析、数据库专业知识到SRE级别的决策——它不仅仅是一个能写代码的模型,而是一个真正理解生产系统的模型。与传统的人工排查流程相比,使用M2.7,我们已经多次将线上生产系统故障的恢复时间缩短至三分钟以内。
在纯粹的编程能力方面,M2.7已经达到了最先进(SOTA)模型的水平。在涵盖多种编程语言的SWE-Pro测试中,M2.7达到了56.22%的准确率,与GPT-5.3-Codex持平。在更贴近现实工程场景的基准测试中,例如SWE Multilingual(76.5)和Multi SWE Bench(52.7),它展示出了更为显著的优势。
这种能力还延伸到了端到端的全项目交付场景。在仓库级别的代码生成基准测试VIBE-Pro上,M2.7得分55.6%,几乎与Opus 4.6持平——这意味着无论需求涉及Web、Android、iOS还是模拟任务,都可以直接交给M2.7来完成。
更值得关注的是它对复杂工程系统的深刻理解。在高度考验系统级理解能力的Terminal Bench 2(57.0%)和NL2Repo(39.8%)测试中,M2.7的表现同样扎实。这进一步证实了它不仅擅长生成代码,还能深入理解软件系统的运行逻辑和协作动态。
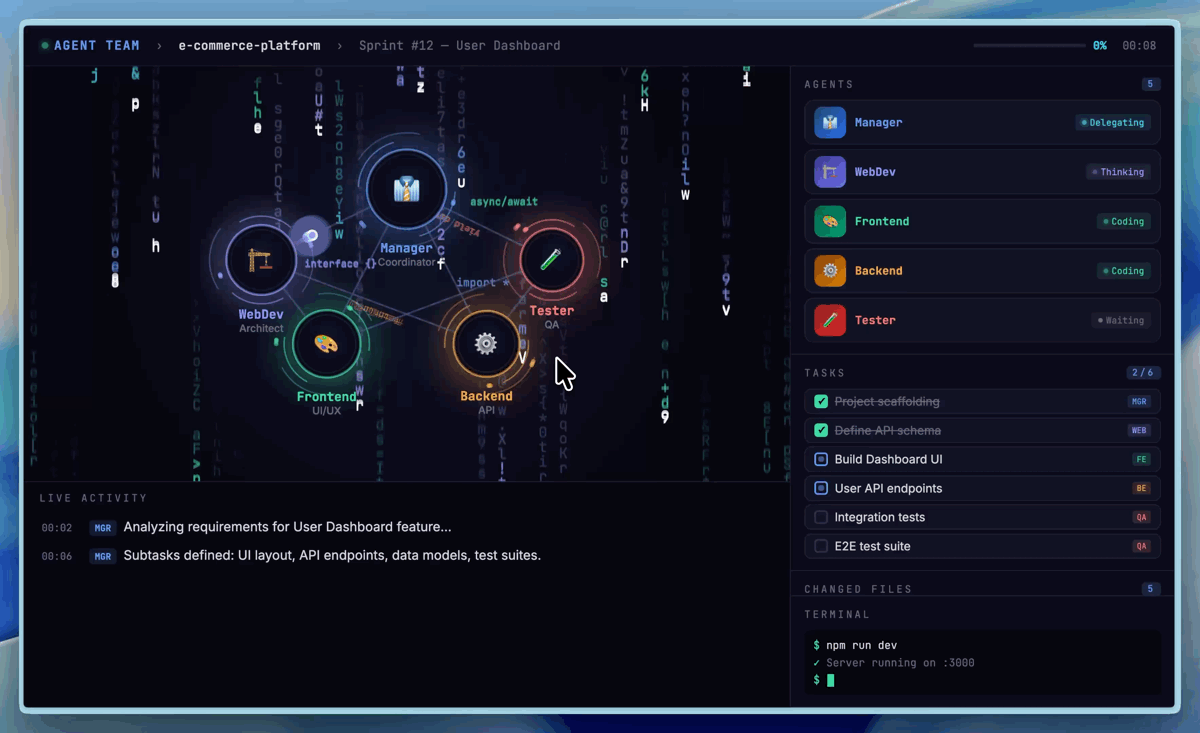
为了提高开发效率,一个尤为重要的功能是原生的智能体团队(多智能体协作)。智能体团队对模型提出了范式级别的要求:角色边界、对抗性推理、协议遵守以及行为差异化——这些不能仅仅通过Prompt实现,而必须内化为模型的原生能力。在智能体团队场景中,模型需要稳定地锚定其角色身份,主动挑战队友的逻辑和伦理盲区,并在复杂的状态机内做出自主决策。以下是我们内部用于产品原型开发的智能体团队设置,其中包含构建产品原型的最小化组织。
专业办公
除了软件工程之外,智能体在办公场景中的用处也越来越大。我们认为这归结于两项核心能力:
领域专业知识与任务交付能力。 模型需要具备各个领域的专业知识并理解用户需求。在衡量这项能力的GDPval-AA评估中,M2.7在45个模型中取得了1495的ELO评分,仅次于Opus 4.6、Sonnet 4.6和GPT5.4,超越了GPT5.3。对于最常见的办公文档处理任务,我们系统性地优化了模型处理Word、Excel和PPT的能力。在各种智能体线束中,M2.7不仅可以基于模板和技能直接生成文件,还可以跟随用户的交互指令对现有文件进行多轮高保真编辑,最终生成可编辑的交付成果。
与复杂环境交互的能力。 泛化的日常场景意味着模型必须灵活地适应各种上下文,调用多种多样的技能和工具,并在长时间的交互中保持稳定的指令遵循。M2.7在这些方面取得了实质性的改进。在Toolathon上,M2.7的准确率达到了46.3%,跻身全球第一梯队。现实工作场景中的智能体线束也往往需要理解和调用大量复杂技能。在MM Claw测试中,M2.7在面对40个复杂技能(每个技能超过2000 tokens)时,保持了97%的技能依从率。
我们测试了该模型在金融领域的专业熟练度,相比上一代,其能力提升非常显著。例如,在一个包含阅读研究报告和对公司未来收入进行建模的场景中,M2.7可以自主阅读公司的年度报告和财报电话会议记录,交叉参考多份研报,独立设计假设并构建收入预测模型,然后根据模板制作PPT和研究报告——像初级分析师一样理解、做出判断并产生输出,同时在多轮互动中进行自我纠正。来自从业人员的反馈是,这些输出已经可以直接作为初稿进入后续的工作流程中。下面是一个针对台积电(TSMC)的案例。
任务:基于台积电的年度报告和财报电话会议信息,为台积电建立一个收入模型。阅读多份研报,设计相应的假设,基于最新信息对台积电的收入进行建模,然后根据PPT模板制作PPT,并撰写Word文档研究报告。
最近OpenClaw的爆火代表了一个繁荣的智能体生态系统,我们很高兴我们的M2系列模型为社区的繁荣做出了贡献。基于OpenClaw中常用的任务,我们构建了一个名为MM Claw的评估集,涵盖了工作和生活中广泛的现实需求——从个人学习计划,到办公文档处理和交付、定期的专业研究与投资建议,再到代码开发和维护。M2.7在这一测试中取得了接近Sonnet 4.6的水平,准确率为62.7%。
娱乐体验
随着OpenClaw和类似的个人智能体的出现,我们注意到除了完成工作之外,许多用户也希望模型拥有高情商和人设一致性。设定好角色后,用户开始像对待朋友一样与OpenClaw进行互动。我们认为这提供了一个将智能体模型的使用范围从纯粹的生产力工具扩展到互动娱乐领域的机会。为此,我们在M2.7中加强了角色一致性和对话能力。
基于此,我们搭建了一个初步的Demo:OpenRoom。这是一个基于智能体线束的互动系统,它将AI互动从纯文本流中解放出来,置于一个万物皆可交互的Web GUI空间内。在这里,角色设定不再是冰冷的Prompt提示块;对话驱动着整个体验,生成实时的视觉反馈和场景互动,角色会主动与他们所处的环境互动。我们认为这个框架具有极高的可扩展性,并且可以随着智能体能力的提高和社区的发展而不断演进,从而探索人类与智能体交互的全新方式。
为了鼓励在这一领域的探索,我们开源了初始演示版本(其中大部分代码是由AI编写的):
MiniMax M2.7现已在MiniMax Agent和MiniMax API平台上全面开放使用。我们期待用户和开发者使用M2.7探索出更多有趣的用例。
- MiniMax Agent:agent.minimax.io
- API:platform.minimax.io
- Coding Plan:platform.minimax.io/subscribe/coding-plan
- Intelligence with Everyone.(与所有人共享智能)
结语
第三百七十八篇博文写完,开心!!!!
今天,也是充满希望的一天。



