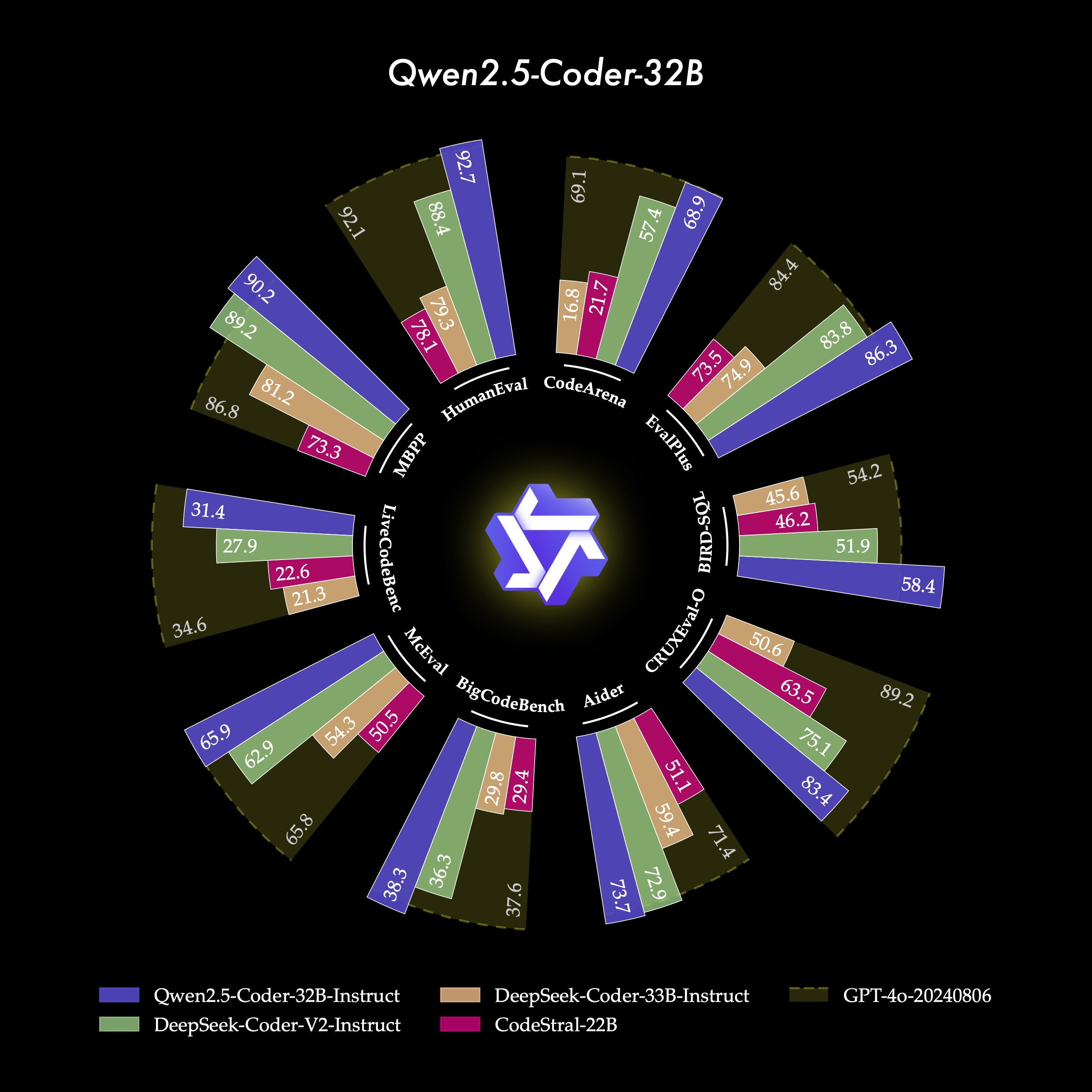
前言Qwen2.5-Coder 全系列: 强大、多样、实用。
github: https://github.com/QwenLM/Qwen2.5-Coder
huggingface: https://huggingface.co/col
2024-11-24










