
00221 NLP Course - Using pretrained models ubuntu
前言
模型中心(Model Hub)简化了选择合适模型的过程,使得在任何下游库中使用这些模型只需几行代码。让我们来看看如何实际使用这些模型,以及如何回馈社区。
假设我们正在寻找一个基于法语的模型,能够执行掩码填充任务。
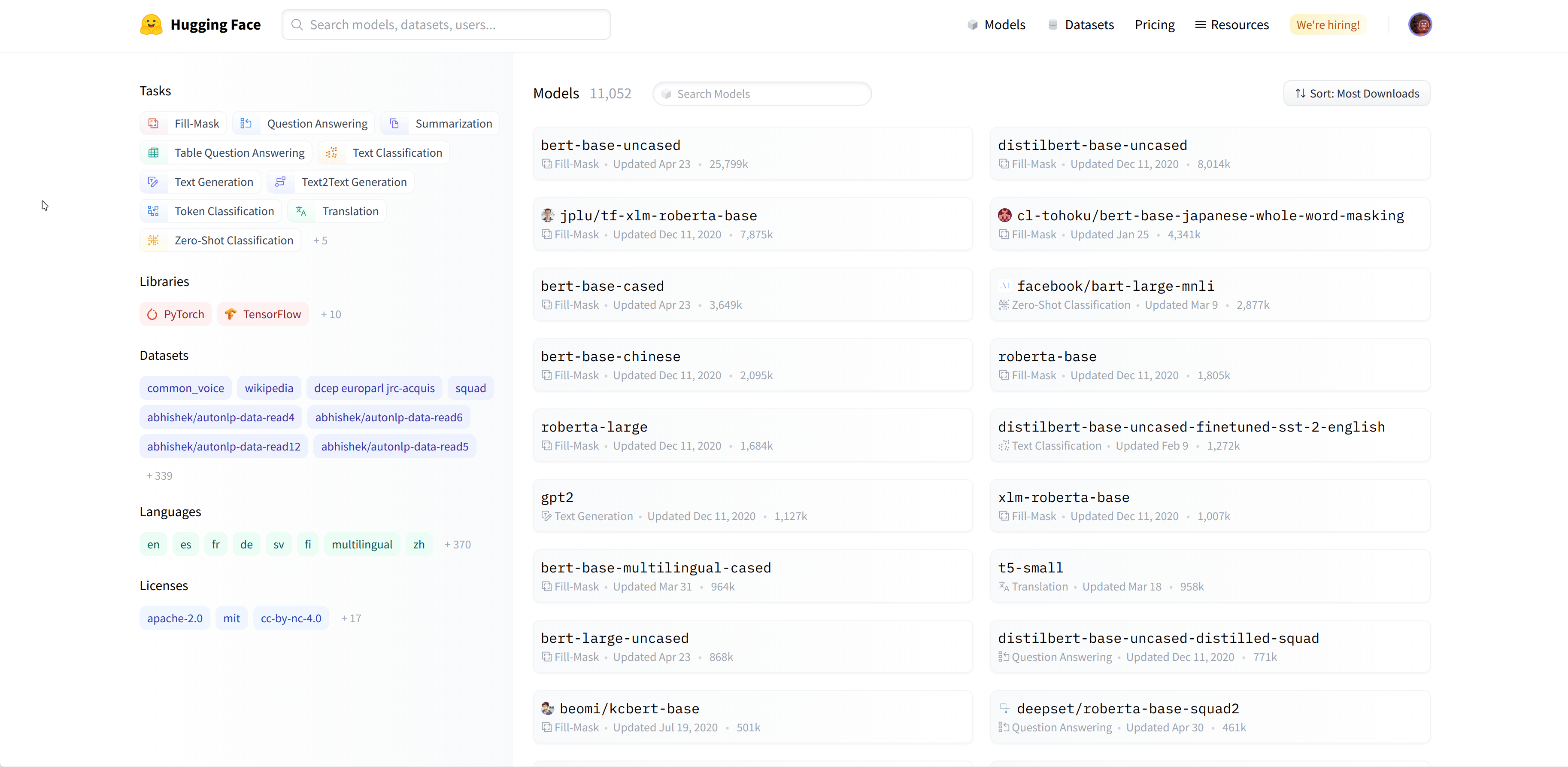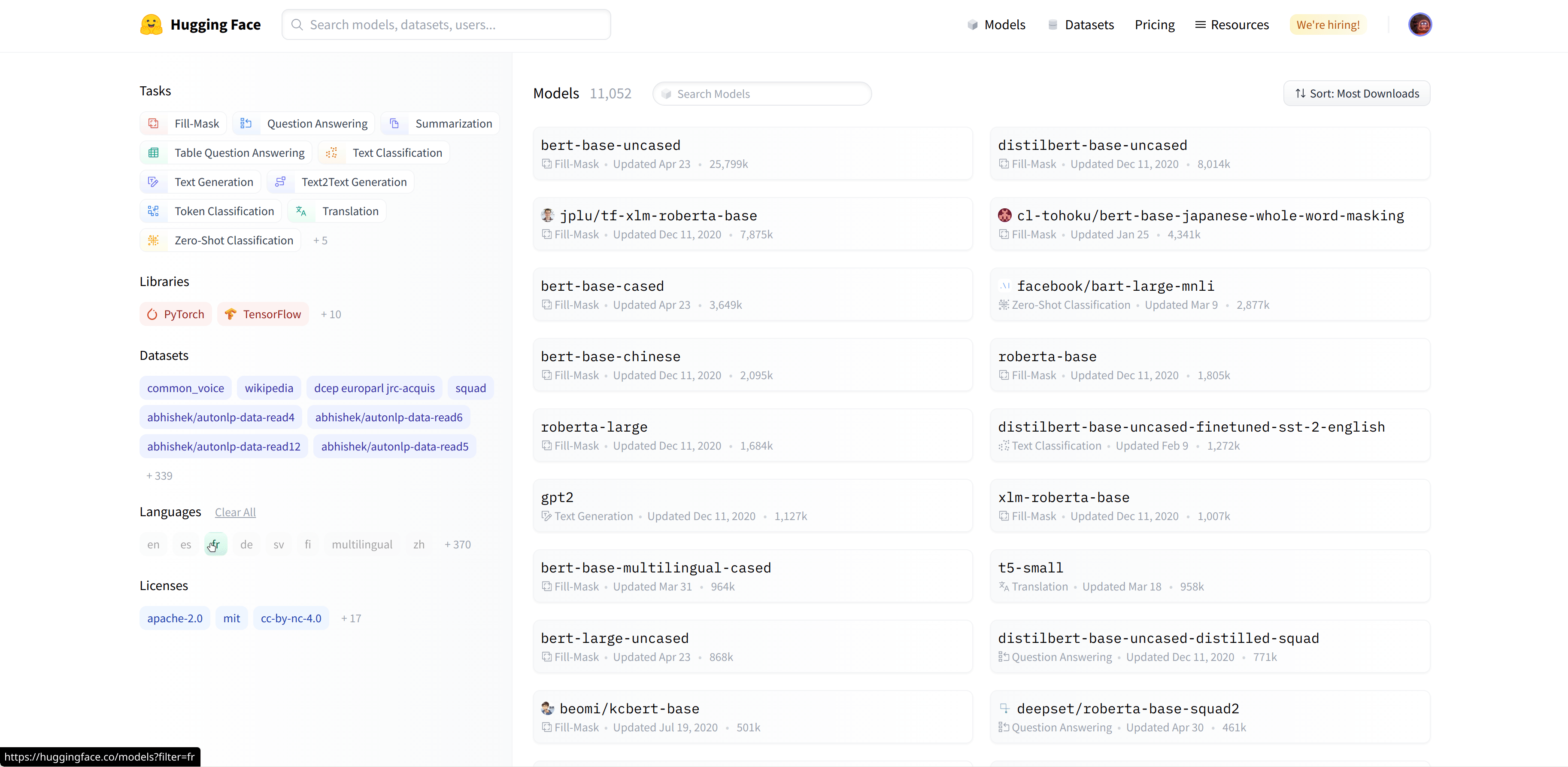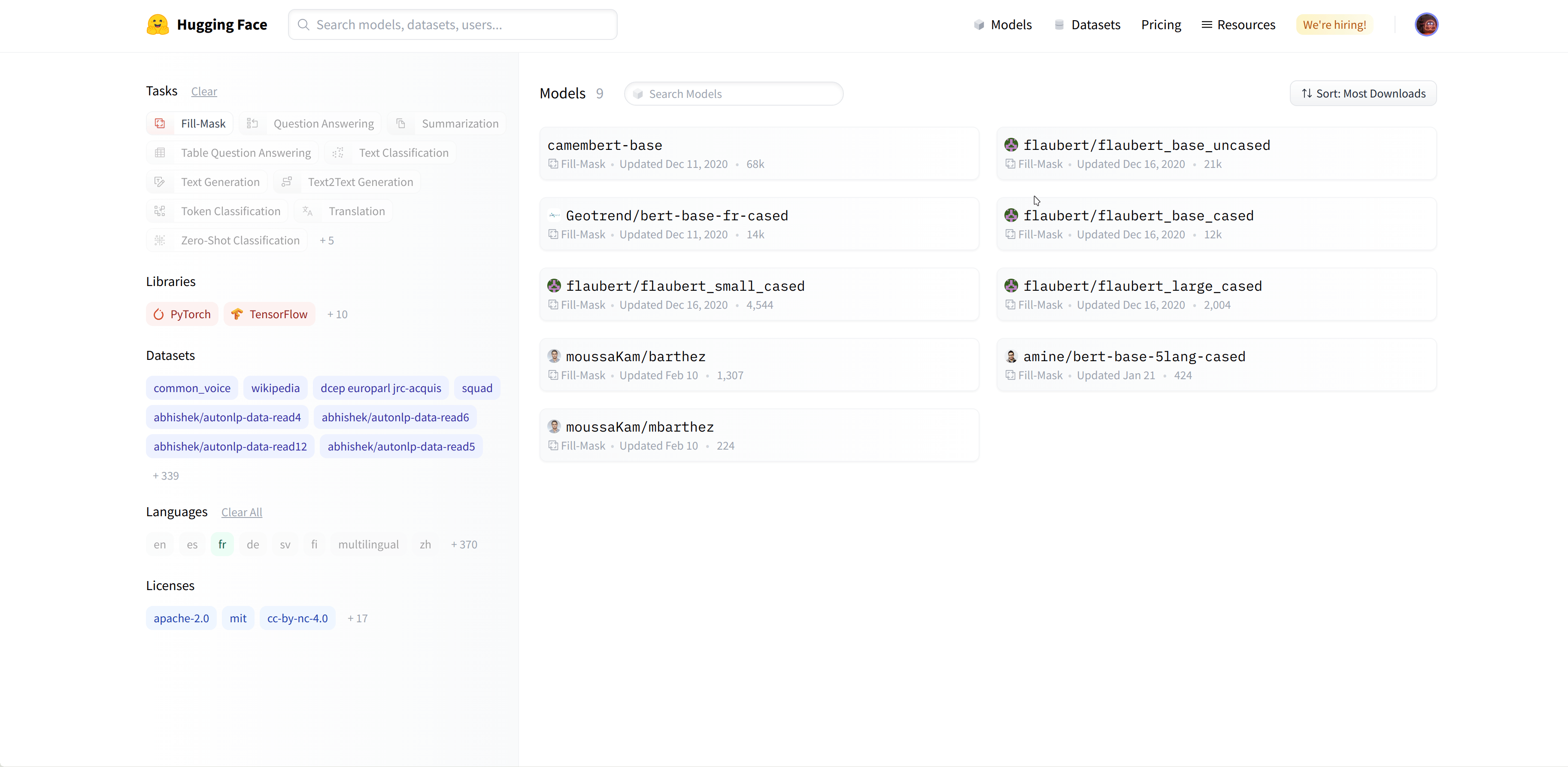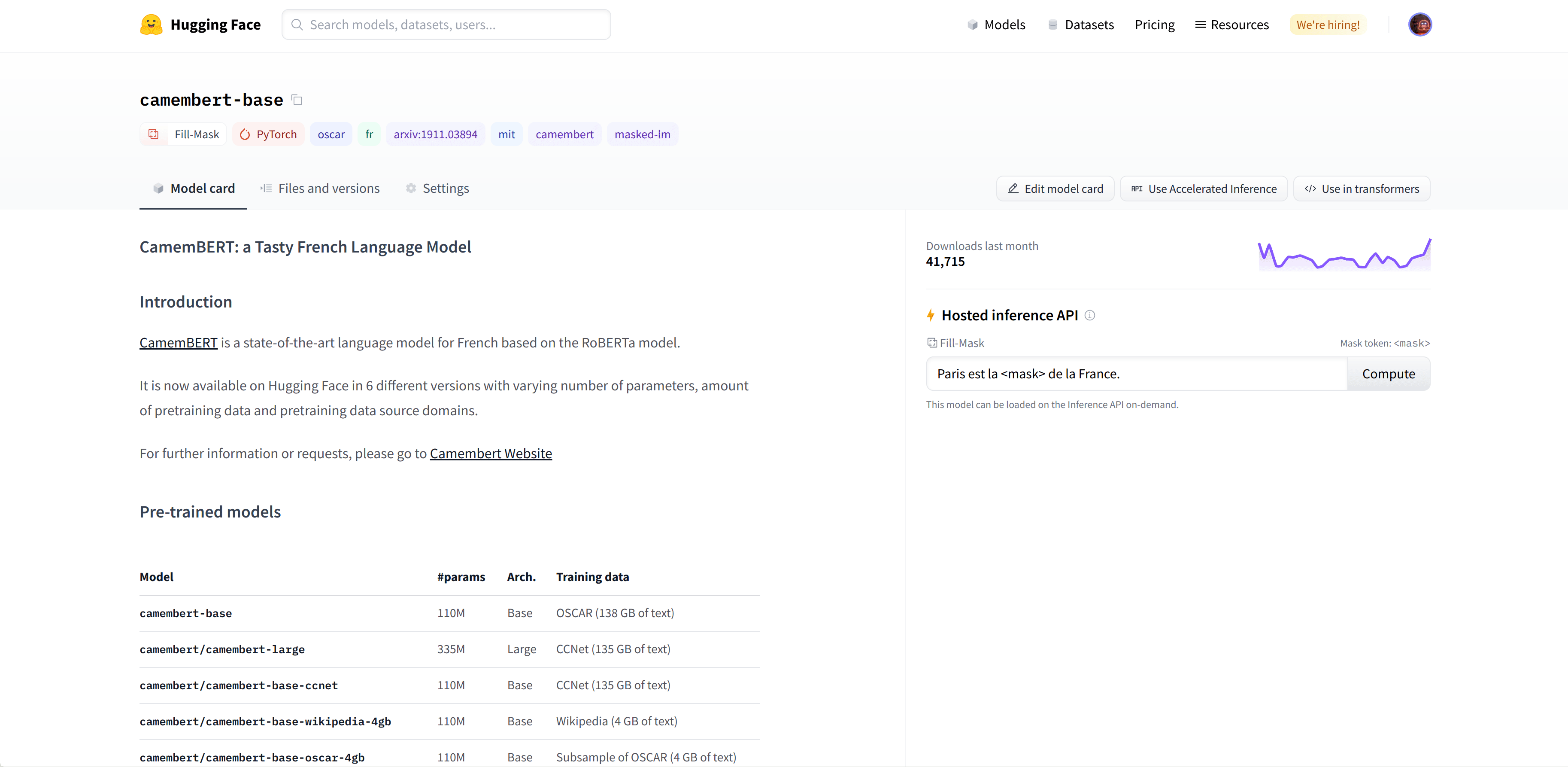
我们选择camembert-base检查点来尝试使用。我们只需要这个标识符camembert-base就可以开始使用它了!正如你在前面的章节中看到的,我们可以使用pipeline()函数来实例化它:
1 | from transformers import pipeline |
1 | [ |
如你所见,在管道中加载模型非常简单。你需要注意的唯一一件事是,所选择的检查点是否适合它将要执行的任务。例如,这里我们在fill-mask管道中加载了camembert-base检查点,这是完全没问题的。但如果我们在这个检查点中加载text-classification管道,结果将没有任何意义,因为camembert-base的头部不适合这个任务!我们建议使用Hugging Face Hub界面中的任务选择器来选择合适的检查点:
你也可以直接使用模型架构来实例化检查点:
1 | from transformers import CamembertTokenizer, CamembertForMaskedLM |
然而,我们建议使用Auto类,因为这些类在设计上是与架构无关的。虽然前面的代码示例限制了用户只能加载适用于CamemBERT架构的检查点,但使用Auto类可以简化切换检查点的过程:
1 | from transformers import AutoTokenizer, AutoModelForMaskedLM |
当使用预训练模型时,请确保检查它是如何训练的,使用了哪些数据集,它的局限性以及它的偏见。所有这些信息都应该在其模型卡上标明。
src link: https://huggingface.co/learn/nlp-course/chapter4/2
Operating System: Ubuntu 22.04.4 LTS
参考文档
结语
第二百二十一篇博文写完,开心!!!!
今天,也是充满希望的一天。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 LuYF-Lemon-love の Blog!
 wechat
wechat alipay
alipay
相关推荐







