前言
数据集地址:https://huggingface.co/datasets/open-r1/Mixture-of-Thoughts
数据集摘要
Mixture-of-Thoughts是从DeepSeek-R1提炼出的350k验证推理轨迹的精选数据集。该数据集跨越数学、编码和科学任务,旨在教语言模型逐步推理。它被用于Open R1项目训练OpenR1-Distill-7B,这是一种SFT模型,从相同的基础模型复制deepseek-ai/DeepSeek-R1-Distill-Qwen-7B的推理能力。
要加载数据集,请运行:
from datasets import load_dataset
dataset = load_dataset("open-r1/Mixture-of-Thoughts", "all", split="train")
# Load a specific domain
dataset_math = load_dataset("open-r1/Mixture-of-Thoughts", "math", split="train")数据集构成
Mixture-of-Thoughts由三个领域组成:数学、代码和科学。每个领域都包含推理轨迹,旨在教语言模型逐步推理。数据集的结构如下:
- math:数学问题的93.7k推理跟踪,来自open-r1/OpenR1-Math-220k的default子集
- code:Python和C++中竞争编程问题的83.1k推理跟踪,来自open-r1/codeforces-cots的solutions和solutions_w_editorials子集
- science:科学问题的173k推理痕迹,来自nvidia/Llama-Nemotron-Post-Training-Dataset的science子集
- all:包含来自三个域的所有推理痕迹,共350k痕迹。
策展方法论
为了优化数据混合,我们遵循Phi-4-reasoning tech report中描述的相同方法论,即可以根据每个域独立优化混合,然后组合成一个数据集。对于每个消融,我们每个时期都在AIME 2024、GPQA Diamond和LiveCodeBench v4上进行评估,并采用性能最佳的模型检查点。下图显示了每个单独域上的训练后open-r1/Qwen2.5-Math-7B-RoPE-300k与最终混合的结果:
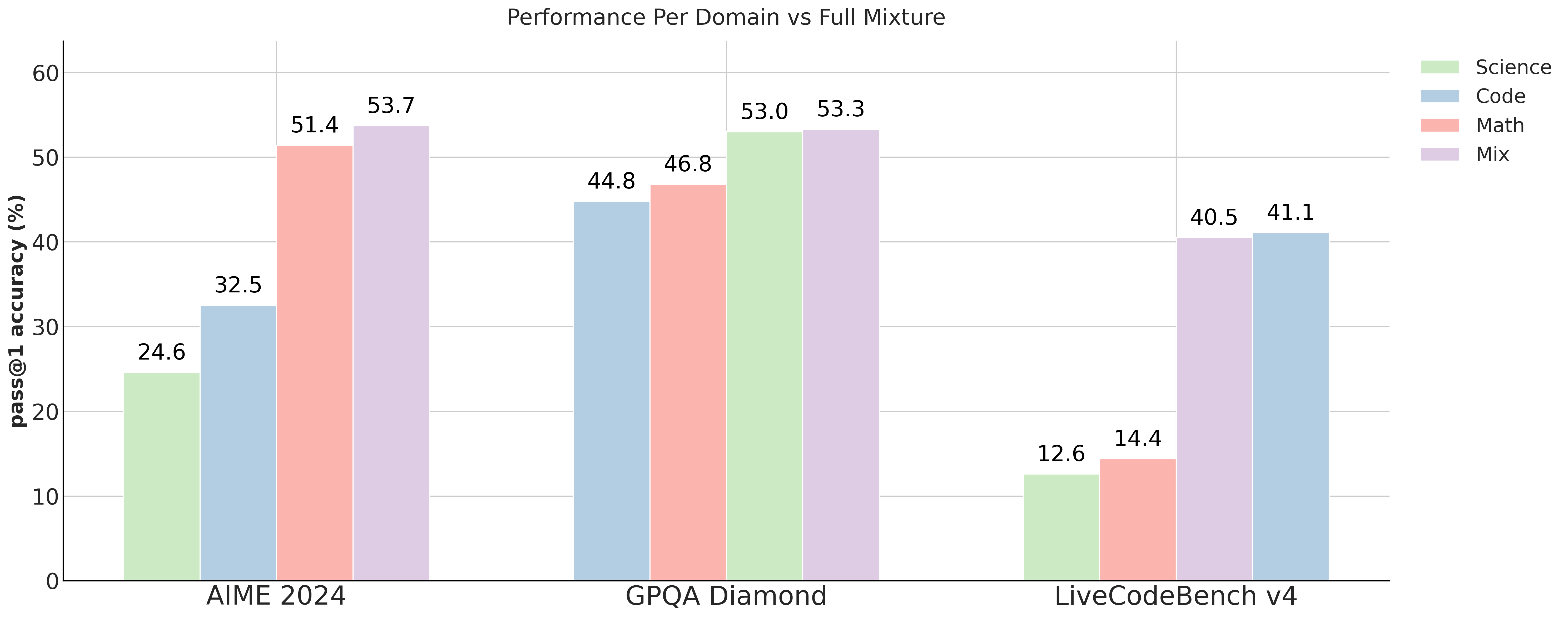
总的来说,我们发现对所有域的训练同时产生最佳结果。有关优化每个域的数据混合的更多详细信息,请参阅下面的小节。
我们使用LiveCodeBench v4在消融期间加速评估,因为它包含了v5的大约一半问题,但仍然代表了完整的基准测试。
Code
在open-r1/OlympicCoder-7B的开发过程中,我们观察到在C++中生成R1推理跟踪在具有挑战性的IOI 2024 benchmark上产生了更好的结果,而Python跟踪在LiveCodeBench(仅限Python的基准测试)上产生了更好的结果。因此,为了优化数据混合,我们使用了来自以下open-r1/codeforces-cots子集的C++和Python跟踪的混合:
- solutions:我们提示R1解决问题并在C++中生成代码。
- solutions_py:与solutions相同,但提示R1在Python中生成代码。
- solutions_w_editorials:我们提示R1解决问题并生成代码,同时也为其提供了人工编写的解决方案。
- solutions_w_editorials_py:与solutions_w_editorials相同,但提示R1在Python中生成代码。
下图显示了我们在这些子集上消融的演变,使用Qwen/Qwen2.5-Coder-7B-Instruct作为基本模型:
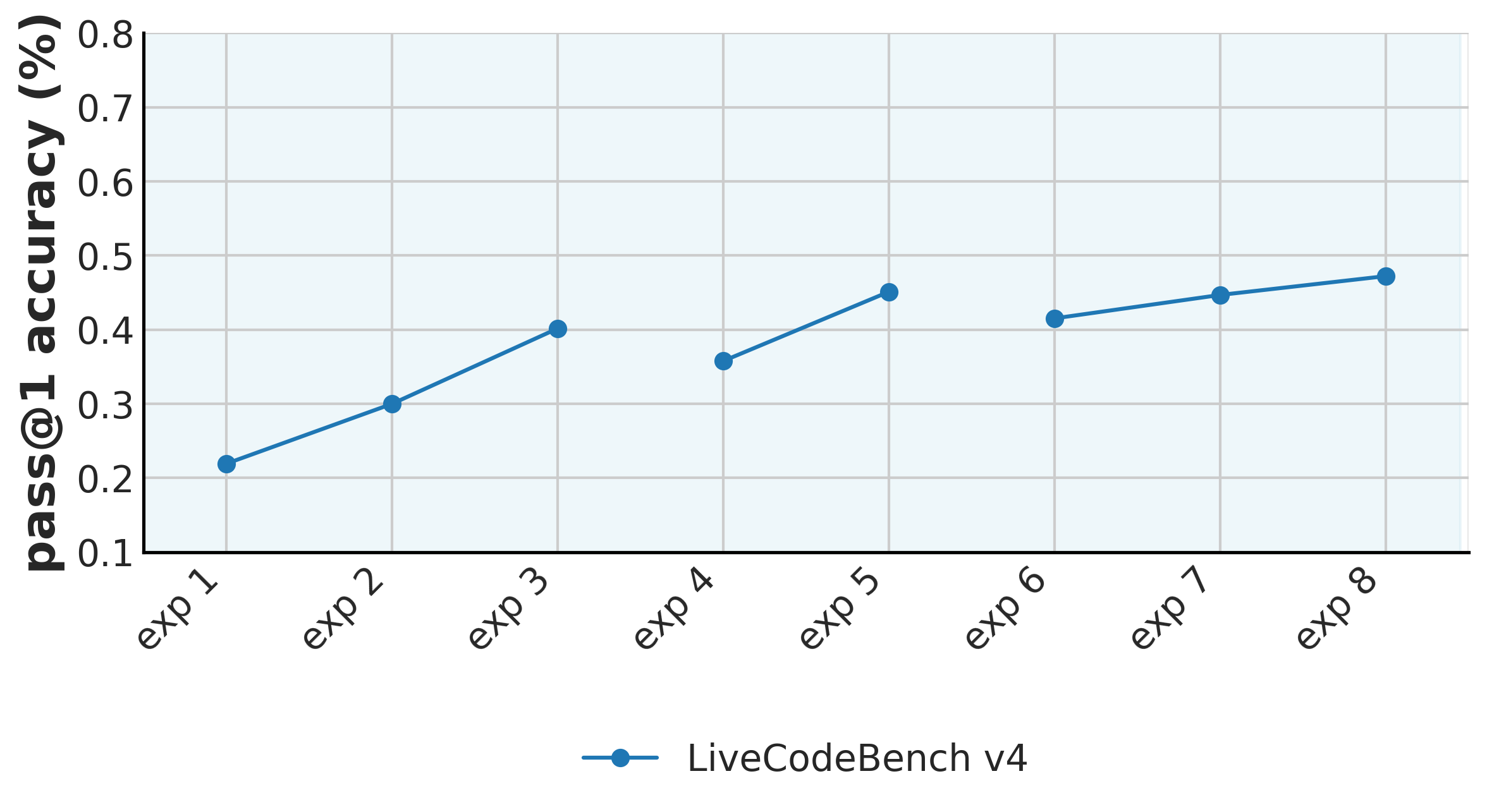
各项实验对应的内容如下:
- exp1 - exp3:在 solutions(解决方案)子集上,将学习率分别从 1e-5 调整为 2e-5 和 4e-5,以进行扩展测试。
- exp4 - exp5:衡量在 solutions_w_editorials(带解析的解决方案)子集上进行训练,与在 solutions 和 solutions_w_editorials 两个子集的合并数据上进行训练,两者之间的效果差异。
- exp6 - exp9:衡量掺入来自 solutions_py 和 solutions_w_editorials_py 子集的 Python 代码轨迹所带来的影响。其中,exp6 合并了 solutions_w_editorials 和 solutions_w_editorials_py 两个子集;exp7 合并了 solutions 和 solutions_py 两个子集;最后,exp8 则将所有四个子集进行了合并。
我们发现,结合C++和Python跟踪的所有子集在LiveCodeBench上产生了最佳结果。我们还发现,使用这种数据混合来微调open-r1/Qwen2.5-Coder-7B-RoPE-300k导致了可比的性能改进,这表明了我们管理策略的有效性。
Math
在数学领域,我们主要致力于比较 open-r1/OpenR1-Math-220k 数据集中的default子集与extended子集。default子集包含 93.7k 条推理轨迹,而extended子集则额外包含了 131k 条轨迹,其中的问题比default子集的更为简单。下图展示了以 Qwen/Qwen2.5-Math-7B-RoPE-300k 作为基础模型时,模型在各个子集上的性能表现:
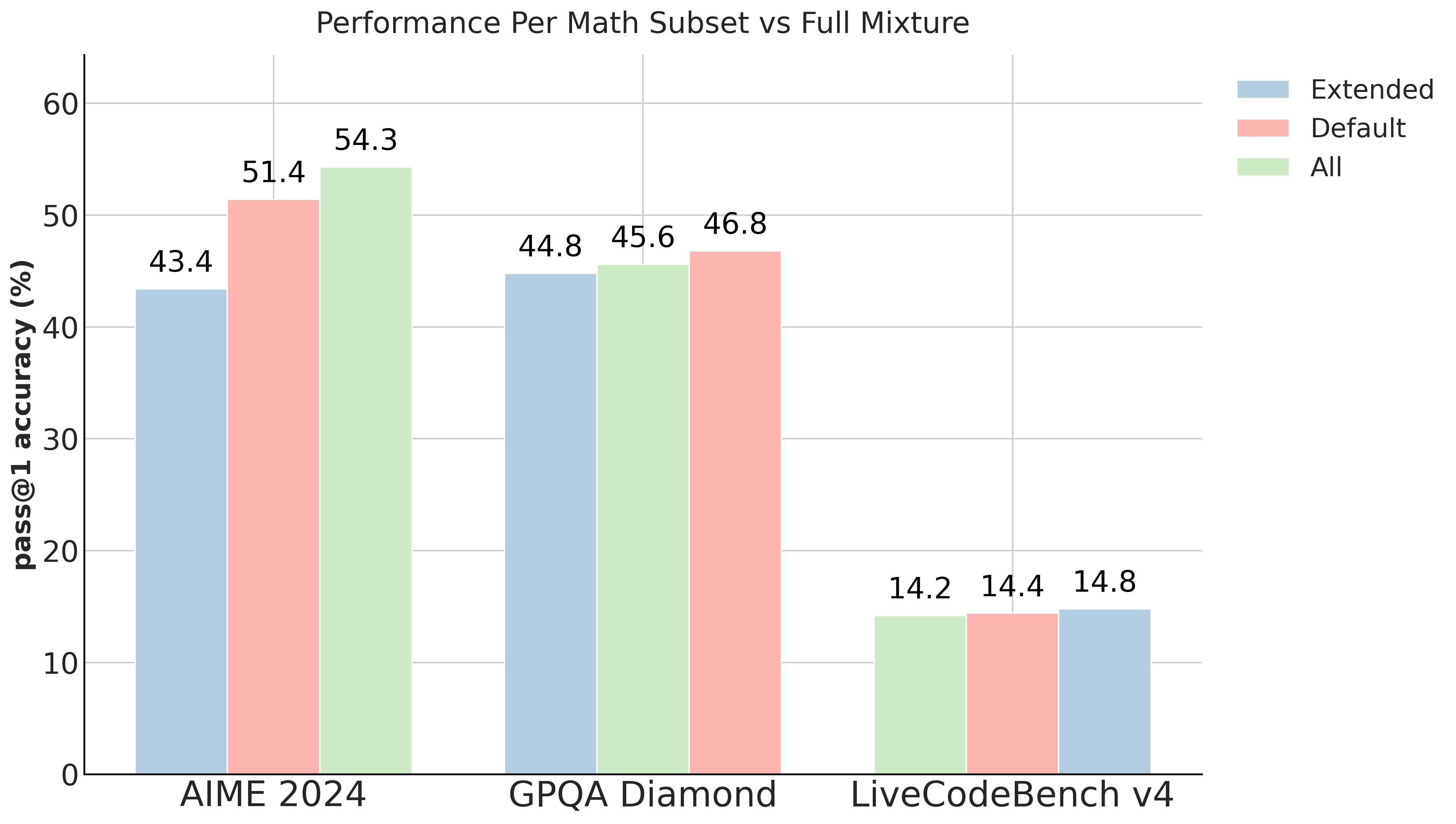
总体而言,我们发现,仅在默认子集上进行训练的效果优于仅在扩展子集上进行训练,而将两个子集合并进行训练则能取得最佳效果。尽管如此,我们最终决定在最终的混合数据集中仅采用默认子集,因为若将两者都包含在内,虽然性能会有适度提升,但会导致数据集的规模显著增加。
Science
在科学领域,我们使用了 nvidia/Llama-Nemotron-Post-Training-Dataset 数据集中的science子集,该子集包含 483k 条推理轨迹。然而,我们发现该子集规模过大,无法全部使用,因为将其完整纳入会导致数据集的体量大幅增加。因此,我们从中筛选出了一个未使用任何 Qwen 模型进行提示(prompt)预处理的轨迹子集——更多细节请参阅相关讨论。经过筛选,我们得到了 173k 条推理轨迹,并在对学习率进行消融实验后,将这部分数据用于最终的混合数据集。
引用
如果您发现此数据集对您自己的工作有用,请考虑如下引用它,以及您正在使用的特定域的来源:
@misc{openr1,
title = {Open R1: A fully open reproduction of DeepSeek-R1},
url = {https://github.com/huggingface/open-r1},
author = {Hugging Face},
month = {January},
year = {2025}
}open-r1/codeforces-cots
@misc{penedo2025codeforces,
title={CodeForces CoTs},
author={Guilherme Penedo and Anton Lozhkov and Hynek Kydlíček and Loubna Ben Allal and Edward Beeching and Agustín Piqueres Lajarín and Quentin Gallouédec and Nathan Habib and Lewis Tunstall and Leandro von Werra},
year={2025},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/datasets/open-r1/codeforces-cots}}
}open-r1/OpenR1-Math-220k
@misc{lozhkov2025openr1math220k,
title={OpenR1-Math-220k},
author={Anton Lozhkov and Hynek Kydlíček and Loubna Ben Allal and Guilherme Penedo and Edward Beeching and Quentin Gallouédec and Nathan Habib and Lewis Tunstall and Leandro von Werra},
year={2025},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/datasets/open-r1/OpenR1-Math-220k}}
}nvidia/Llama-Nemotron-Post-Training-Dataset
@misc{bercovich2025llamanemotronefficientreasoningmodels,
title={Llama-Nemotron: Efficient Reasoning Models},
author={Akhiad Bercovich and Itay Levy and Izik Golan and Mohammad Dabbah and Ran El-Yaniv and Omri Puny and Ido Galil and Zach Moshe and Tomer Ronen and Najeeb Nabwani and Ido Shahaf and Oren Tropp and Ehud Karpas and Ran Zilberstein and Jiaqi Zeng and Soumye Singhal and Alexander Bukharin and Yian Zhang and Tugrul Konuk and Gerald Shen and Ameya Sunil Mahabaleshwarkar and Bilal Kartal and Yoshi Suhara and Olivier Delalleau and Zijia Chen and Zhilin Wang and David Mosallanezhad and Adi Renduchintala and Haifeng Qian and Dima Rekesh and Fei Jia and Somshubra Majumdar and Vahid Noroozi and Wasi Uddin Ahmad and Sean Narenthiran and Aleksander Ficek and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Igor Gitman and Ivan Moshkov and Wei Du and Shubham Toshniwal and George Armstrong and Branislav Kisacanin and Matvei Novikov and Daria Gitman and Evelina Bakhturina and Jane Polak Scowcroft and John Kamalu and Dan Su and Kezhi Kong and Markus Kliegl and Rabeeh Karimi and Ying Lin and Sanjeev Satheesh and Jupinder Parmar and Pritam Gundecha and Brandon Norick and Joseph Jennings and Shrimai Prabhumoye and Syeda Nahida Akter and Mostofa Patwary and Abhinav Khattar and Deepak Narayanan and Roger Waleffe and Jimmy Zhang and Bor-Yiing Su and Guyue Huang and Terry Kong and Parth Chadha and Sahil Jain and Christine Harvey and Elad Segal and Jining Huang and Sergey Kashirsky and Robert McQueen and Izzy Putterman and George Lam and Arun Venkatesan and Sherry Wu and Vinh Nguyen and Manoj Kilaru and Andrew Wang and Anna Warno and Abhilash Somasamudramath and Sandip Bhaskar and Maka Dong and Nave Assaf and Shahar Mor and Omer Ullman Argov and Scot Junkin and Oleksandr Romanenko and Pedro Larroy and Monika Katariya and Marco Rovinelli and Viji Balas and Nicholas Edelman and Anahita Bhiwandiwalla and Muthu Subramaniam and Smita Ithape and Karthik Ramamoorthy and Yuting Wu and Suguna Varshini Velury and Omri Almog and Joyjit Daw and Denys Fridman and Erick Galinkin and Michael Evans and Katherine Luna and Leon Derczynski and Nikki Pope and Eileen Long and Seth Schneider and Guillermo Siman and Tomasz Grzegorzek and Pablo Ribalta and Monika Katariya and Joey Conway and Trisha Saar and Ann Guan and Krzysztof Pawelec and Shyamala Prayaga and Oleksii Kuchaiev and Boris Ginsburg and Oluwatobi Olabiyi and Kari Briski and Jonathan Cohen and Bryan Catanzaro and Jonah Alben and Yonatan Geifman and Eric Chung and Chris Alexiuk},
year={2025},
eprint={2505.00949},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.00949},
}结语
第三百五十四篇博文写完,开心!!!!
今天,也是充满希望的一天。



