前言
在第5节中,我们创建了来自🤗 Datasets仓库的GitHub问题和评论的数据集。在本节中,我们将使用这些信息构建一个搜索引擎,帮助我们找到关于库的最紧迫问题的答案!
src link: https://huggingface.co/learn/nlp-course/chapter5/6
Operating System: Ubuntu 22.04.4 LTS
参考文档
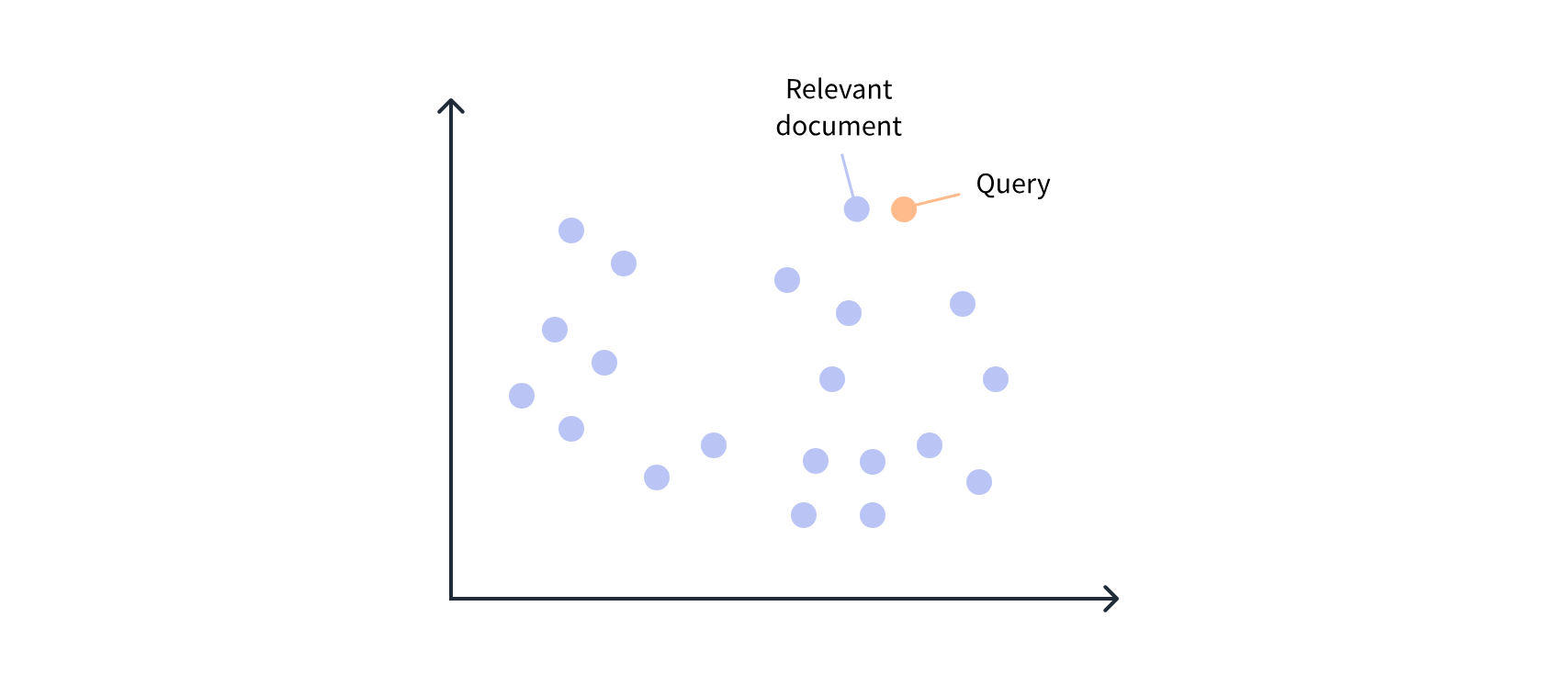
使用嵌入进行语义搜索
正如我们在第一章中看到的,基于Transformer的语言模型将文本跨度中的每个标记表示为一个嵌入向量。事实证明,可以通过“池化”各个嵌入向量来为整个句子、段落或(在某些情况下)文档创建一个向量表示。然后,这些嵌入向量可以通过计算每个嵌入向量的点积相似度(或其他相似度度量)来在语料库中找到相似的文档,并返回重叠最大的文档。
在本节中,我们将使用嵌入向量来开发一个语义搜索引擎。这些搜索引擎与传统的基于在查询中匹配关键词与文档的方法相比,提供了几个优势。
加载数据集并准备
我们需要做的第一件事是下载我们的GitHub问题数据集,所以让我们像往常一样使用load_dataset()函数。
from datasets import load_dataset
issues_dataset = load_dataset("lewtun/github-issues", split="train")
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 2855
})在这里,我们在load_dataset()中指定了默认的训练分割,所以它返回了一个Dataset而不是DatasetDict。首先要处理的事情是过滤掉拉取请求,因为这些通常很少用于回答用户查询,并且会在我们的搜索引擎中引入噪声。现在你应该已经很熟悉了,我们可以使用Dataset.filter()函数来排除数据集中的这些行。同时,让我们也过滤掉没有评论的行,因为它们对用户查询提供不了任何答案。
issues_dataset = issues_dataset.filter(
lambda x: (x["is_pull_request"] == False and len(x["comments"]) > 0)
)
issues_datasetDataset({
features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'performed_via_github_app', 'is_pull_request'],
num_rows: 771
})我们可以看到数据集中有很多列,而我们构建搜索引擎时大多数都不需要。从搜索的角度来看,最有信息量的列是title(标题)、body(正文)和comments(评论),而html_url为我们提供了回到源问题的链接。让我们使用Dataset.remove_columns()函数来删除其余的列。
columns = issues_dataset.column_names
columns_to_keep = ["title", "body", "html_url", "comments"]
columns_to_remove = set(columns_to_keep).symmetric_difference(columns)
issues_dataset = issues_dataset.remove_columns(columns_to_remove)
issues_datasetDataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 771
})为了创建我们的嵌入向量,我们将每个评论与问题的标题和正文相结合,因为这些字段通常包含有用的上下文信息。由于我们的评论列目前是每个问题的评论列表,我们需要“展开”这个列,以便每行包含一个(html_url, title, body, comment)元组。在Pandas中,我们可以使用DataFrame.explode()函数来实现这一点,该函数为列表状列中的每个元素创建一个新行,同时复制所有其他列的值。为了看到这一过程,让我们首先切换到Pandas DataFrame格式。
issues_dataset.set_format("pandas")
df = issues_dataset[:]如果我们检查这个DataFrame的第一行,可以看到这个问题关联了四条评论。
df["comments"][0].tolist()['the bug code locate in :\r\n if data_args.task_name is not None:\r\n # Downloading and loading a dataset from the hub.\r\n datasets = load_dataset("glue", data_args.task_name, cache_dir=model_args.cache_dir)',
'Hi @jinec,\r\n\r\nFrom time to time we get this kind of `ConnectionError` coming from the github.com website: https://raw.githubusercontent.com\r\n\r\nNormally, it should work if you wait a little and then retry.\r\n\r\nCould you please confirm if the problem persists?',
'cannot connect,even by Web browser,please check that there is some problems。',
'I can access https://raw.githubusercontent.com/huggingface/datasets/1.7.0/datasets/glue/glue.py without problem...']当我们展开df时,我们期望为这四条评论各得到一行。让我们检查一下是否如此。
comments_df = df.explode("comments", ignore_index=True)
comments_df.head(4)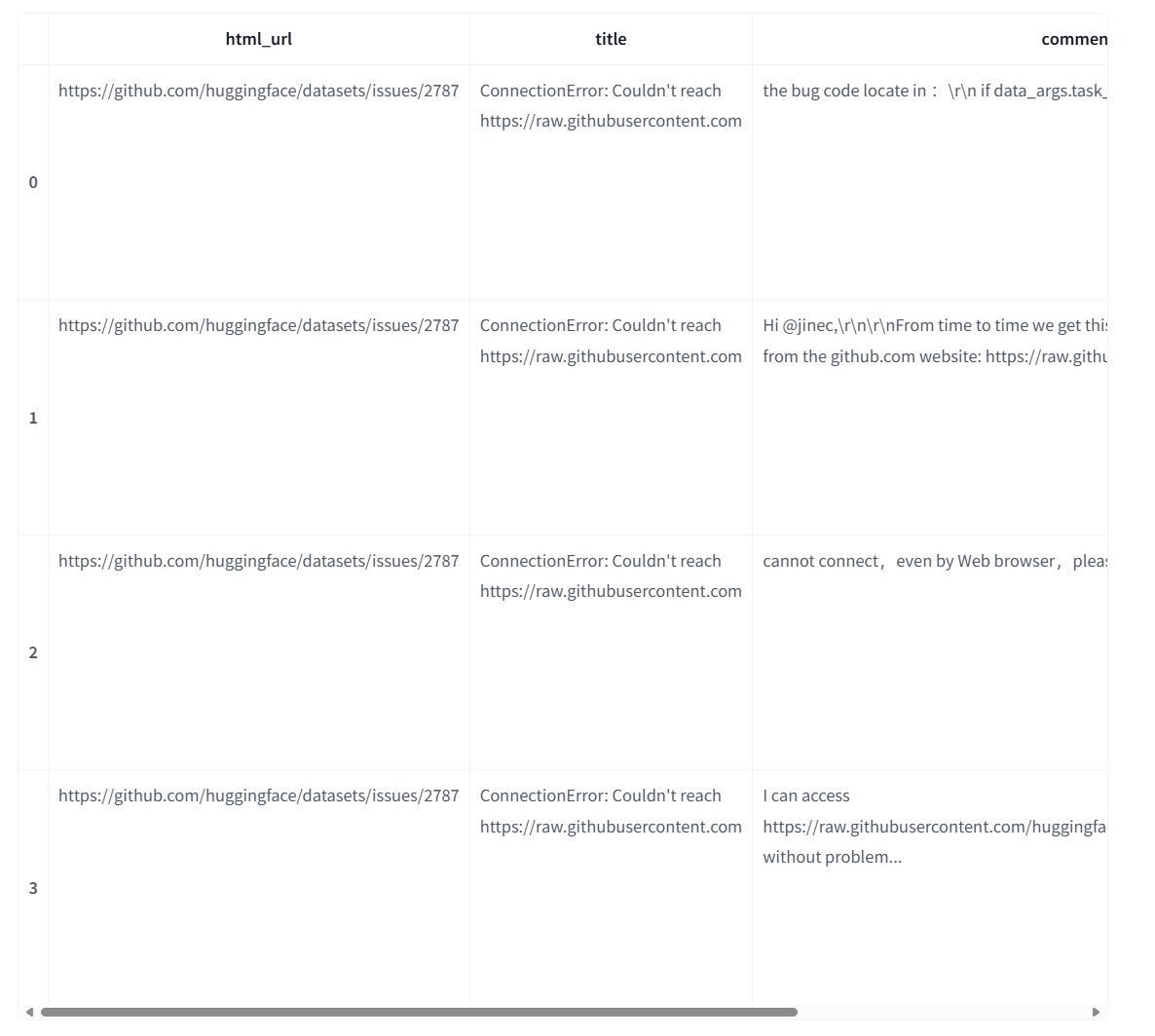
太好了,我们可以看到行已经被复制,评论列包含了单独的评论!现在我们已经完成了Pandas的操作,可以通过将DataFrame加载到内存中快速切换回一个Dataset。
from datasets import Dataset
comments_dataset = Dataset.from_pandas(comments_df)
comments_datasetDataset({
features: ['html_url', 'title', 'comments', 'body'],
num_rows: 2842
})好的,这给了我们几千条评论来处理!
✏️ 试一试!看看你是否可以使用Dataset.map()来展开issues_dataset的评论列,而不需要使用Pandas。这有点棘手;你可能会发现🤗 Datasets文档中的“批量映射”部分对这个任务很有用。
现在我们每行有一条评论,让我们创建一个新的comments_length列,它包含每条评论的单词数量。
comments_dataset = comments_dataset.map(
lambda x: {"comment_length": len(x["comments"].split())}
)我们可以使用这个新列来过滤掉短评论,这些评论通常包括像“cc @lewtun”或“Thanks!”这样的内容,对我们的搜索引擎不相关。选择过滤器的精确数字没有固定标准,但大约15个单词似乎是一个不错的起点。
comments_dataset = comments_dataset.filter(lambda x: x["comment_length"] > 15)
comments_datasetDataset({
features: ['html_url', 'title', 'comments', 'body', 'comment_length'],
num_rows: 2098
})我们已经清理了一下数据集,现在让我们将问题标题、描述和评论一起连接到一个新的文本列中。像往常一样,我们将编写一个简单的函数,我们可以将其传递给Dataset.map()。
def concatenate_text(examples):
return {
"text": examples["title"]
+ " \n "
+ examples["body"]
+ " \n "
+ examples["comments"]
}
comments_dataset = comments_dataset.map(concatenate_text)我们终于准备好创建一些嵌入向量了!让我们来看一看。
创建文本嵌入向量
我们在第二章中看到,我们可以使用AutoModel类获得令牌嵌入。我们需要做的只是选择一个合适的检查点来加载模型。幸运的是,有一个叫做sentence-transformers的库专门用于创建嵌入。如库的文档所述,我们的用例是不对称语义搜索的一个例子,因为我们有一个简短的查询,我们希望在较长的文档(如问题评论)中找到答案。文档中的方便的模型概览表指出,multi-qa-mpnet-base-dot-v1检查点在语义搜索方面具有最佳性能,因此我们将将其用于我们的应用程序。我们还将使用相同的检查点加载令牌生成器:
from transformers import AutoTokenizer, AutoModel
model_ckpt = "sentence-transformers/multi-qa-mpnet-base-dot-v1"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)为了加快嵌入过程,将模型和输入放在GPU设备上有帮助,我们现在就这样做吧:
import torch
device = torch.device("cuda")
model.to(device)正如我们之前提到的,我们希望将GitHub问题语料库中的每个条目表示为一个单一的向量,所以我们需要以某种方式“池化”或平均我们的令牌嵌入。一种流行的方法是对我们模型的输出执行CLS池化,我们只需收集特殊[CLS]令牌的最后一个隐藏状态。下面的函数对我们来说很有效:
def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0]接下来,我们将创建一个辅助函数,该函数将对文档列表进行分词,将张量放在GPU上,将它们输入到模型中,并最终对输出应用CLS池化:
def get_embeddings(text_list):
encoded_input = tokenizer(
text_list, padding=True, truncation=True, return_tensors="pt"
)
encoded_input = {k: v.to(device) for k, v in encoded_input.items()}
model_output = model(**encoded_input)
return cls_pooling(model_output)我们可以通过向函数输入语料库中的第一个文本条目并检查输出形状来测试函数是否正常工作:
embedding = get_embeddings(comments_dataset["text"][0])
embedding.shapetorch.Size([1, 768])太好了,我们已经将语料库中的第一个条目转换成了一个768维的向量!我们可以使用Dataset.map()将我们的get_embeddings()函数应用到语料库中的每一行,所以让我们按照以下方式创建一个新的嵌入列:
embeddings_dataset = comments_dataset.map(
lambda x: {"embeddings": get_embeddings(x["text"]).detach().cpu().numpy()[0]}
)请注意,我们已经将嵌入向量转换成了NumPy数组——这是因为当我们尝试使用FAISS对它们进行索引时,🤗 Datasets需要这种格式,我们接下来就会这样做。
使用FAISS进行高效的相似性搜索
现在我们有一个嵌入向量数据集,我们需要一种方法来搜索它们。为此,我们将使用🤗 Datasets中的一个特殊数据结构,称为FAISS索引。FAISS(Facebook AI Similarity Search的缩写)是一个库,提供了高效的算法来快速搜索和聚类嵌入向量。
FAISS背后的基本思想是创建一个称为索引的特殊数据结构,它允许找到与输入嵌入相似的嵌入。在🤗 Datasets中创建一个FAISS索引很简单——我们使用Dataset.add_faiss_index()函数,并指定我们想要索引的数据集的哪一列:
embeddings_dataset.add_faiss_index(column="embeddings")我们现在可以通过使用Dataset.get_nearest_examples()函数进行最近邻查找来对这个索引执行查询。让我们通过首先嵌入一个问题来测试这一点,如下列出的一个问题:
question = "How can I load a dataset offline?"
question_embedding = get_embeddings([question]).cpu().detach().numpy()
question_embedding.shapetorch.Size([1, 768])就像文档一样,我们现在有一个768维的向量来表示查询,我们可以将其与整个语料库进行比较,以找到最相似的嵌入向量:
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5
)Dataset.get_nearest_examples()函数返回一个分数元组,对查询和文档之间的重叠进行排名,以及一组相应的样本(在这里,最好的5个匹配)。让我们将这些收集到一个pandas.DataFrame中,这样我们就可以轻松地对它们进行排序:
import pandas as pd
samples_df = pd.DataFrame.from_dict(samples)
samples_df["scores"] = scores
samples_df.sort_values("scores", ascending=False, inplace=True)现在我们可以遍历前几行,看看我们的查询与可用评论匹配得有多好:
for _, row in samples_df.iterrows():
print(f"COMMENT: {row.comments}")
print(f"SCORE: {row.scores}")
print(f"TITLE: {row.title}")
print(f"URL: {row.html_url}")
print("=" * 50)
print()"""
COMMENT: Requiring online connection is a deal breaker in some cases unfortunately so it'd be great if offline mode is added similar to how `transformers` loads models offline fine.
@mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
SCORE: 25.505046844482422
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: The local dataset builders (csv, text , json and pandas) are now part of the `datasets` package since #1726 :)
You can now use them offline
\`\`\`python
datasets = load_dataset("text", data_files=data_files)
\`\`\`
We'll do a new release soon
SCORE: 24.555509567260742
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: I opened a PR that allows to reload modules that have already been loaded once even if there's no internet.
Let me know if you know other ways that can make the offline mode experience better. I'd be happy to add them :)
I already note the "freeze" modules option, to prevent local modules updates. It would be a cool feature.
----------
> @mandubian's second bullet point suggests that there's a workaround allowing you to use your offline (custom?) dataset with `datasets`. Could you please elaborate on how that should look like?
Indeed `load_dataset` allows to load remote dataset script (squad, glue, etc.) but also you own local ones.
For example if you have a dataset script at `./my_dataset/my_dataset.py` then you can do
\`\`\`python
load_dataset("./my_dataset")
\`\`\`
and the dataset script will generate your dataset once and for all.
----------
About I'm looking into having `csv`, `json`, `text`, `pandas` dataset builders already included in the `datasets` package, so that they are available offline by default, as opposed to the other datasets that require the script to be downloaded.
cf #1724
SCORE: 24.14896583557129
TITLE: Discussion using datasets in offline mode
URL: https://github.com/huggingface/datasets/issues/824
==================================================
COMMENT: > here is my way to load a dataset offline, but it **requires** an online machine
>
> 1. (online machine)
>import datasets
data = datasets.load_dataset(…)
data.save_to_disk(/YOUR/DATASET/DIR)
2. copy the dir from online to the offline machine 3. (offline machine)import datasets
data = datasets.load_from_disk(/SAVED/DATA/DIR)
HTH. SCORE: 22.893993377685547 TITLE: Discussion using datasets in offline mode URL: https://github.com/huggingface/datasets/issues/824 ================================================== COMMENT: here is my way to load a dataset offline, but it **requires** an online machine 1. (online machine) \`\`\` import datasets data = datasets.load_dataset(...) data.save_to_disk(/YOUR/DATASET/DIR) \`\`\` 2. copy the dir from online to the offline machine 3. (offline machine) \`\`\` import datasets data = datasets.load_from_disk(/SAVED/DATA/DIR) \`\`\` HTH. SCORE: 22.406635284423828 TITLE: Discussion using datasets in offline mode URL: https://github.com/huggingface/datasets/issues/824 ================================================== """
不错!我们的第二次搜索似乎与查询匹配。
✏️试一试!创建你自己的查询,看看你是否可以在检索到的文档中找到一个答案。你可能需要增加Dataset.get_nearest_examples()中的k参数来扩大搜索范围。
结语
第二百四十三篇博文写完,开心!!!!
今天,也是充满希望的一天。



