
00010-Linux 基础-ubuntu
前言
Linux 是 UNIX 操作系统的一个克隆系统,但是 Linux 操作系统是开源的。因此 Linux 自从但是以来就是企业级服务器的首选操作系统。它和 Git 一直是学生从学校到企业的两个拦路虎。所以学习 Linux 操作系统是必要的。
操作系统:Ubuntu 20.04.4 LTS。
参考文档
初识 Linux 操作系统
Linux 的发展历程
1991
年初
林纳斯 · 托瓦兹开始在一台 386sx 兼容微机上学习 minix 操作系统。
04
林纳斯 · 托瓦兹开始酝酿并着手编制自己的操作系统。
04-13
林纳斯 · 托瓦兹在 comp.os.minix 上宣布自己已经成功地将 bash 移植到了 minix 上了。
10-05
林纳斯 · 托瓦兹在 comp.os.minix 宣布 Linux 内核已经诞生。
1992
Linux 与其他 GNU 软件结合,完全自由的操作系统 GNU/Linux 诞生。
1993
Linux 0.99 的代码量有十万行,用户有 10 万个左右。
1994
03
Linux 1.0 发布,公有 17 万行代码。不久正式采用 GPL 协议。
Linux 特性
-
Linux 是一个基于文件的操作系统。甚至像鼠标键盘等硬件都被抽象成一个设备文件来管理。
-
多个用户可以同时登录,每个用户同时可以运行多个应用程序。
-
是一个自由软件,免费且开源。
POSIX ,英文全称为 Portable Operating System Interface for Computing Systems,是由 IEEE 和 ISO/IEC 开发的一套接口标准,保证所编制的应用程序在源代码一级可以在多种操作系统上可移植。中文名为 可移植操作系统接口。
Linux 发行版,对于初学者接触的两个最常见的发行版为
-
CentOS Linux 发行版是一个稳定、可预测、可管理和可重现的平台,源自红帽 Linux( RHEL )的源代码。
-
Ubuntu 发行版最大的特点就是具有优秀易用的桌面环境,基于 Debian Linux 发行版。
Linux 内核
Linux 内核主要包含 5 个子系统:进程调度、内存管理、虚拟文件系统、网路接口和进程间通信。
-
进程调度 SCHED 是操作系统对进程的多种状态之间的转换策略。
-
SCHED_OTHER: 分时调度策略(默认),用于针对普通进程的时间片轮转调度策略。
-
SCHED_FIFO: 实时调度策略,是针对运行的实时性要求比较高、运行时间短的进程调度策略。
-
SCHED_RR: 实时调度策略,是针对实时性要求比较高、运行时间比较长的进程调度策略。
-
-
内存管理 MMU
-
内存管理是多个进程间的内存共享策略。指的是虚拟内存。
-
虚拟内存可以让进程拥有比实际物理内存更大的内存。
-
每个进程的虚拟内存存在不同的地址空间,多个进程的虚拟内存不会冲突。
-
-
虚拟文件系统 VFS
- Linux 支持多种文件系统,目前最常用的文件系统为 ext2 和 ext3。
-
网路接口
-
网络接口包括网络协议和驱动程序。
-
网络协议是一种网络传输的通信标准。
-
网络驱动程序是硬件设备的驱动程序。
-
-
进程间通信
- 通信方式包括管道、信号、消息队列、共享内存和套接字。

Linux 目录
Linux 文件系统是一个树状结构,只有一个单独的顶级目录结构,叫做根目录,更目录的子目录结构相对固定。
-
bin: 二进制文件目录,存储了可执行程序。
-
sbin: root 用户使用的一些二进制可执行程序。
-
etc: 应用程序的配置文件目录。
-
lib: 存储了一些动态链接库和静态链接库。
-
media: 挂载目录,挂载外部设备:光驱,扫描仪等。
-
mnt: 临时挂载目录,如 U 盘。
-
proc: 内存使用的映射目录,操作系统使用。
-
tmp: 临时目录,存放临时数据,重启电脑时,数据被自动删除。
-
boot: 存储了开机相关的配置。
-
home: 普通用户的家目录。
-
root: root 用户的家目录。
-
dev: 设备目录,如 键盘、鼠标。
-
lost+found: 存储用于电脑异常关闭/崩溃时恢复系统的文件。
-
opt: 第三方软件的安装目录。
-
var: 存储日志等经常发生变化的文件。
-
usr: 系统资源目录。
-
/usr/bin: 可执行的二进制应用程序。
-
/usr/games: 游戏目录。
-
/usr/include: 包含标准头文件。
-
/usr/local: 第三方软件安装目录。
-
文件路径
相对路径
./: 等价于.,代表当前目录。../: 等价于..,代表上一级目录。
绝对路径:从系统磁盘起始节点开始描述的路径。如 /usr/games。
命令解析器
命令解析器经常有 bash 和 shell 两个名字。shell 是 Bourne 为 Unix 操作系统写的命令解析器。bash 是 Bourne 为 Linux 操作系统写的命令解析器。
1 | 打印环境变量 |
命令提示行
1 | root@lyfubuntu:~/local# |
-
root: 当前登录的用户的用户名。
-
@: at -> 在
-
lyfubuntu: 主机名。
-
~: 表示家目录。
-
~/local: 表示当前用户所在的工作目录。
-
#: 表示当前用户是 root 用户。
-
$: 表示当前用户是普通用户。
命令行快捷键
-
Tab: 命令自动补齐。
-
Ctrl+p: 显示上一个输入的历史命令。等价于 ↑ 键。
-
Ctrl+n: 显示下一个输入的历史命令。等价于 ↓ 键。
-
Ctrl+a: 光标移动到命令行首。等价于 Home 键。
-
Ctrl+e: 光标移动到命令行尾。等价于 End 键。
-
Ctrl+u: 删除光标前的部分字符串。
-
Ctrl+k: 删除光标后的部分字符串。
-
→: 光标向右移动一个字符。
-
←:光标向左移动一个字符。
-
Backspace: 删除光标前的一个字符。
-
Delete: 删除光标后的一个字符。
Vim 的使用
Vim 是 Linux 操作系统中一款功能强大的文本编辑器,支持安装各种插件,但是所有的操作都是通过键盘快捷键操作完成的。Vim 是 Vi 的增强版。
安装
1 | sudo apt install vim |
Vim 的模式
Vim 一共有三种模式,分别是 命令模式,末行模式,编辑模式,默认进入的是 命令模式。
命令模式下的操作
1 | 打开一个文件,如果文件不存在,并且退出的时候进行了保存,文件会被创建。 |
保存退出
1 | 先按住 shift 键,然后连续按两次 z |
代码格式化
1 | 假设写的 c/c++ 代码没有对齐,通过该命令可以对齐代码 |
光标的移动
- ↑ | k: 光标上移
- ↓ | j: 光标下移
- ← | h: 光标左移
- → | l: 光标右移
- 0: 光标移动到行首
- $: 光标移动到行尾
- gg: 光标移动到第一行的开始
- G: 光标移动到最后一行的开始
- nG: 行跳转,n 代表要跳转到哪一行
- n+Enter: 相对跳转 n 行,从光标所在行往下跳 n 行
删除(剪切)命令
- x: 删除光标盖住的字符
- X: 删除光标前边的字符
- dw: 删除光标所在单词的右边字符
- d0: 删除光标前的字符串
- d$ | D: 删除光标后的字符串
- dd: 删除光标所在行
- ndd: 从光标所在行开始删除 n 行
撤销和反撤销
- u: 撤销,等价于 windows 中的 ctrl+z
- Ctrl+r: 反撤销,等价于 windows 中的 ctrl+y
复制和粘贴
- p: 粘贴到光标所在行的下边
- P: 粘贴到光标所在行的上边
- yy: 复制光标所在行
- nyy: 从光标所在行向下复制 n 行
可视模式
- v: 进入字符可视模式( Characterwise visual mode ),文本选择是以字符为单位的。
- V: 进入行可视模式( Linewise visual mode ),文本选择是以行为单位的。
- Ctrl+v: 进入块可视模式( Blockwise visual mode ),可以选择一个矩形形状的文本。
进入到可视模式后
- h: 光标向左移动
- j: 光标向下移动
- k: 光标向上移动
- l: 光标向右移动
- d: 剪切
- y: 复制
- p: 粘贴到光标的后边
- P: 粘贴到光标的前边
代码注释
代码块注释使用块可视模式:
- Ctrl+v 进入块可视模式
- 通过 k 和 j 使得光标上移或者下移,选中多个代码行的开头。
- 选择完毕后,按大写的 I 键,输入注释符。
- 按 Esc 键。
删除代码块注释:
- Ctrl+v 进入块可视模式
- 移动光标选中注释符
- 按 d 键
替换
- r: 替换光标后的单个字符
- R: 替换光标后的多个字符,按 Esc 键结束替换
查找
- /:
n从当前位置向下,N从当前位置向上 - ?:
n从当前位置向上,N从当前位置向下 - #: ‘n’ 从当前位置向上,
N从当前位置向下,光标需要先放置在被搜索的关键字上。
查看 man 文档
man 文档一共有 9 个章节,具体如下:
- section 1: Linux 提供的所有 shell 命令
- section 2: 系统函数(由内核提供)
- section 3: 库调用函数(程序库中的函数)
- section 4: 特殊文件(通常存放在 /dev 目录中)
- section 5: 系统配置文件格式和约定,比如:/etc/passwd
- section 6: 游戏
- section 7: 杂项(包括宏包和约定)
- section 8: 系统管理命令(通常针对 root 用户)
- section 9: 内核例程(非标准)
1 | 打开 man 文档首页 |
Vim 的命令模式下
1 | 首先将光标放在要查看的函数上 |
切换到编辑模式
- i: 从光标的前边开始输入
- a: 从光标的后边开始输入
- o: 在光标下边新建行,在新行中输入
- s: 删除光标盖住的字符,从删除的字符位置开始输入
- I: 从当前行行首开始输入
- A: 从当前行行尾开始输入
- O: 在光标上边新建行,在新行中输入
- S: 删除当前行,在当前行开始输入
- Rsc: 从编辑模式退回到命令模式
末行模式下的操作
命令模式和末行模式相互切换
1 | 命令模式切换到末行模式 |
保存退出
- q: 退出,如果没有保存文件,Vim 会给出提示是否要保存
- q!: 直接退出,不保存
- w: 保存,不退出
- wq | x: 保存退出
替换
1 | /g 表示做整行替换 |
分屏
- sp: 水平分屏,多个窗口垂直排列,多个窗口中显示同一文件里的内容
- vsp: 垂直分屏,多个窗口水平排列,多个窗口中显示同一个文件里的内容
- Ctrl+w+w: 光标在打开的屏幕之间切换,按住 Ctrl 然后按两次 w
- qall: 同时退出多个屏幕
- wqall: 同时保存退出多个屏幕
- sp 文件名:分屏的同时指定打开的文件的名字
- vsp 文件名:分屏的同时指定打开的文件的名字
1 | 在打开文件的时候指定分屏 |
行跳转
1 | :行号 # 输入完行号之后敲 Enter 键 |
执行 shell 命令
1 | 语法 |
Vim 配置文件
- ~/.vimrc: 用户级别的配置文件
- /ect/vim/vimrc: 系统级别的配置文件
- 用户级别的配置文件优先级高
Vim 插件快速按安装
vimplus: An automatic configuration program for vim.
安装vimplus
1 | git clone https://github.com/chxuan/vimplus.git ~/.vimplus |
设置Nerd Font
为防止vimplus显示乱码,需设置linux终端字体为Droid Sans Mono Nerd Font。
- 在nerd-fonts 的 readme.md 文件的 Patched Fonts 处下载字体

- 进入complete文件夹,选择下载
-
双击下载的字体文件,进行安装
-
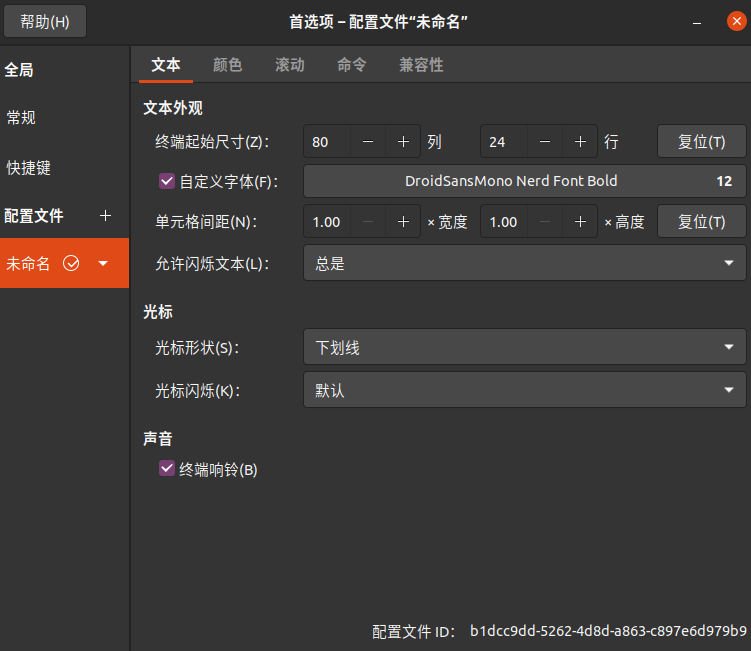
在 terminal 设置,右击选择配置文件首选项(P)
-
选择字体

多用户支持
将vimplus在某个用户下安装好后,若需要在其他用户也能够使用vimplus,则执行
1 | sudo ./install_to_user.sh username1 username2 //替换为真实用户名 |
更新vimplus
紧跟vimplus的步伐,尝鲜新特性
1 | ./update.sh |
自定义
- ~/.vimrc 为 vimplus 的默认配置,一般不做修改
- ~/.vimrc.custom.plugins 为用户自定义插件列表,用户增加、卸载插件请修改该文件
- ~/.vimrc.custom.config 为用户自定义配置文件,一般性配置请放入该文件,可覆盖 ~/.vimrc 里的配置
插件列表
| 插件 | 说明 |
|---|---|
| cpp-mode | 提供生成函数实现、函数声明/实现跳转、.h .cpp切换等功能(I’m author:smile:) |
| vim-edit | 方便的文本编辑插件(I’m author:smile:) |
| change-colorscheme | 随心所欲切换主题(I’m author:smile:) |
| prepare-code | 新建文件时,生成预定义代码片段(I’m author:smile:) |
| vim-buffer | vim缓存操作(I’m author:smile:) |
| vimplus-startify | vimplus开始页面 |
| tagbar | 使用 preservim/tagbar 的最新版本,taglist 的替代品,显示类/方法/变量 |
| vim-plug | 比 Vundle 下载更快的插件管理软件 |
| YouCompleteMe | 史上最强大的基于语义的自动补全插件,支持C/C++、C#、Python、PHP等语言 |
| NerdTree | 代码资源管理器 |
| vim-nerdtree-syntax-highlight | NerdTree文件类型高亮 |
| nerdtree-git-plugin | NerdTree显示git状态 |
| vim-devicons | 显示文件类型图标 |
| Airline | 可以取代 powerline 的状态栏美化插件 |
| auto-pairs | 自动补全引号、圆括号、花括号等 |
| LeaderF | 比 ctrlp 更强大的文件的模糊搜索工具 |
| ack | 强大的文本搜索工具 |
| vim-surround | 自动增加、替换配对符的插件 |
| vim-commentary | 快速注释代码插件 |
| vim-repeat | 重复上一次操作 |
| vim-endwise | if/end/endif/endfunction补全 |
| tabular | 代码、注释、表格对齐 |
| vim-easymotion | 强大的光标快速移动工具,强大到颠覆你的插件观 |
| incsearch.vim | 模糊字符搜索插件 |
| vim-fugitive | 集成Git |
| gv | 显示 git 提交记录 |
| vim-slash | 优化搜索,移动光标后清除高亮 |
| echodoc | 补全函数时在命令栏显示函数签名 |
| vim-smooth-scroll | 让翻页更顺畅 |
| clever-f.vim | 强化f和F键 |
快捷键
以下是部分快捷键,可通过vimplus的,h命令查看 vimplus帮助文档。
| 快捷键 | 说明 |
|---|---|
, |
Leader Key |
<leader>n |
打开/关闭代码资源管理器 |
<leader>t |
打开/关闭函数列表 |
<leader>a |
.h .cpp 文件切换 |
<leader>u |
转到函数声明 |
<leader>U |
转到函数实现 |
<leader>u |
转到变量声明 |
<leader>o |
打开include文件 |
<leader>y |
拷贝函数声明 |
<leader>p |
生成函数实现 |
<leader>w |
单词跳转 |
<leader>f |
搜索~目录下的文件 |
<leader>F |
搜索当前目录下的文本 |
<leader>g |
显示git仓库提交记录 |
<leader>G |
显示当前文件提交记录 |
<leader>gg |
显示当前文件在某个commit下的完整内容 |
<leader>ff |
语法错误自动修复(FixIt) |
<c-p> |
切换到上一个buffer |
<c-n> |
切换到下一个buffer |
<leader>d |
删除当前buffer |
<leader>D |
删除当前buffer外的所有buffer |
vim |
运行vim编辑器时,默认启动开始页面 |
<F5> |
显示语法错误提示窗口 |
<F9> |
显示上一主题 |
<F10> |
显示下一主题 |
<leader>l |
按竖线对齐 |
<leader>= |
按等号对齐 |
Ya |
复制行文本到字母a |
Da |
剪切行文本到字母a |
Ca |
改写行文本到字母a |
rr |
替换文本 |
<leader>r |
全局替换,目前只支持单个文件 |
rev |
翻转当前光标下的单词或使用V模式选择的文本 |
gcc |
注释代码 |
gcap |
注释段落 |
vif |
选中函数内容 |
dif |
删除函数内容 |
cif |
改写函数内容 |
vaf |
选中函数内容(包括函数名 花括号) |
daf |
删除函数内容(包括函数名 花括号) |
caf |
改写函数内容(包括函数名 花括号) |
fa |
查找字母a,然后再按f键查找下一个 |
<leader>e |
快速编辑~/.vimrc文件 |
<leader>s |
重新加载~/.vimrc文件 |
<leader>vp |
快速编辑~/.vimrc.custom.plugins文件 |
<leader>vc |
快速编辑~/.vimrc.custom.config文件 |
<leader>h |
打开vimplus帮助文档 |
<leader>H |
打开当前光标所在单词的vim帮助文档 |
<leader><leader>t |
生成try-catch代码块 |
<leader><leader>y |
复制当前选中到系统剪切板 |
<leader><leader>i |
安装插件 |
<leader><leader>u |
更新插件 |
<leader><leader>c |
删除插件 |
GCC
GCC 是 Linux 操作系统的编译工具集,是 GNU Compiler Collection 的缩写,包含 gcc,g++ 等编译器。这个工具集不仅包含编译器,还包含其他工具集,如 ar、nm 等。支持 X86、ARM、PowerPC、mips 等硬件平台,还支持 Linux、Windows 等软件平台。
安装 GCC
1 | ubuntu |
GCC 工作流程
GCC 编译程序分为 4 个阶段:预处理(预编译)、编译和优化、汇编和链接。
-
预处理:GCC 调用预处理器来完成,包括:展开头文件、宏替换和去掉注释行。
-
编译:GCC 调用编译器对文件进行编译,得到一个汇编文件。
-
汇编:GCC 调用汇编器对文件进行汇编,最终得到一个二进制文件。
-
链接:GCC 调用链接器对程序需要调用的库进行链接,最终得到一个可执行的二进制文件。
各个阶段的的文件
-
源文件,后缀为 .c
-
预处理后的 C 文件,后缀为 .i,预处理参数为 -E
-
编译得到汇编语言的源文件,后缀为 .s,编译参数为 -S
-
汇编得到的二进制文件,后缀为 .o,汇编参数 -c
flowchart LR
C语言源文件:::someclass -- 预处理 --> 预处理后的文件:::someclass -- 编译 --> 汇编文件:::someclass -- 汇编 --> 目标文件:::someclass -- 链接 --> 可执行程序:::someclass
classDef someclass fill:#f9f,stroke:#333,stroke-width:4px;
1 | // 假设程序对应的源文件名为 test.c |
1 | 1. 预处理,-o 指定生成的文件名 |
注:在使用 gcc 编译程序的时候可以通过参数控制内部自动执行几个步骤
1 | 参数 -c 是进行文件的汇编,汇编之前的两步会自动执行 |
GCC 常用参数
注:下面的参数在 gcc 命令中没有位置要求
| gcc 编译选项 | 选项的意义 |
|---|---|
| -E | 预处理指定的源文件,不进行编译 |
| -S | 编译指定的源文件,不进行汇编 |
| -c | 汇编指定的源文件,不进行链接 |
| -o file1 file2 / file2 -o file1 | 将 file2 编译成 file1 |
| -I directory | 指定 include 包含文件的搜索目录 |
| -g | 在编译的时候,生成调试信息,该程序可以被调试器调试 |
| -D | 编译程序的时候,指定一个宏 |
| -w | 不生成任何警告信息 |
| -Wall | 生成所有的警告信息 |
| -On | n的取值范围:0~3。编译器的优化选项一共有 4 个级别,-O0 表示没有优化,-O1 为缺省值,-O3 优化级别最高 |
| -l | 在编译程序的时候,指定使用的库 |
| -L | 在编译程序的时候,搜索的库的路径 |
| -fPIC/fpic | 生成与位置无关的代码 |
| shared | 生成共享目标文件,通常用在建立共享库的时候 |
| -std | 指定 C 方言,如: -std=c99, gcc 默认的方言是 GNU C |
指定生成的文件名( -o )
1 | test.c 写在 -o 之前 |
搜索头文件( -I )
1 | 假设头文件 head.h 在 include 目录中 |
指定一个宏( -D )
1 | // test.c |
1 | 在编译命令中定义这个 DEBUG 宏, |
-D 参数控制是否打印 log。
多文件编译
- 头文件
1 |
|
- 源文件 string.c
1 |
|
- 源文件 main.c
1 |
|
因为头文件是包含在源文件中的,因此在使用 gcc 编译程序的时候不需要指定头文件的名字。
- 直接链接生成可执行程序
1 | 直接生成可执行程序 test |
- 先将源文件汇编成目标文件,然后链接得到可执行程序
1 | 汇编生成二进制目标文件,指定了 -c 参数之后,源文件会自动生成 string.o 和 main.o |
GCC 与 G++
-
在编译阶段(第二个阶段):
-
后缀为 .c 的文件,gcc 把它当作是 C 程序,g++ 把它当作是 C++ 程序。
-
后缀为 .cpp 的文件,两者都会认为是 C++ 程序。
-
g++ 会调用 gcc,对于 C++ 程序,两者是等价的。
-
-
在链接阶段(最后一个阶段):
-
gcc 和 g++ 都可以自动链接到标准 C 库。
-
g++ 可以自动链接到标准 C++ 库,gcc 需要加参数 -lstdc++
-
-
__cplusplus 宏的定义
-
g++ 会自动定义 __cplusplus 宏,但不影响编译 C 程序。
-
gcc 会根据文件后缀名判断是否定义 __cplusplus 宏
-
1 | 编译 C 程序 |
静态链接库和动态链接库
库文件包括静态链接库和动态链接库,使用库的目的:
-
为了使程序更简洁不需要在项目中维护太多的源文件。
-
为了源代码保密。
静态链接库
静态链接库命名规则:
-
Linux 操作系统:以 lib 作为前缀,以 .a 作为后缀,中间是库的名字,即:libxxx.a。
-
Windows 操作系统:以 lib 作为前缀,以 .lib 作为后缀,中间是库的名字,即:libxxx.lib。
生成静态链接库
生成静态链接库需要先对源文件进行汇编操作得到二进制格式的目标文件,然后通过 ar 将目标文件打包得到静态库文件。
ar 的参数:
-
c: 创建一个库,不管库是否存在,都将创建。
-
s: 创建目标文件索引,在创建较大的库时能加快时间。
-
r: 在库中插入模块(替换),默认新的成员添加在库的结尾处,如果模块名已经在库中存在,则替换同名的模块。
1 | 1. 将源文件进行汇编,得到 .o 文件,需要使用参数 -c |
准备测试程序
1 | 目录结构 add.c div.c mult.c sub.c -> 算法的源文件, 函数声明在头文件 head.h |
add.c
1 |
|
sub.c
1 |
|
mult.c
1 |
|
div.c
1 |
|
head.h
1 |
|
main.c
1 |
|
生成静态链接库
1 | 将源文件 add.c, div.c, mult.c, sub.c 进行汇编,得到二进制目标文件 add.o, div.o, mult.o, sub.o |
静态链接库的使用
将静态链接库、头文件和测试程序放到一个目录中准备进行测试。
-
-L: 指定静态链接库所在的目录(相对或者绝对路径)
-
-l: 指定库的名字,需要掐头(lib)去尾(.a),剩下的才是需要的静态链接库的名字
-
-L -l: 参数和参数值之间可以有空格,也可以没有 -L./ -lcalc
1 | gcc main.c -o app -L ./ -l calc |
动态链接库
动态链接库是程序运行时加载的库,当动态链接库正确部署之后,运行的多个程序可以使用同一个加载到内存中的动态链接库,因此在 Linux 操作系统中动态链接库又被称为共享库。
动态链接库是目标文件的集合,库中的函数和变量的地址是相对地址,而静态链接库中使用的是绝对地址。动态链接库的真实地址是在应用程序加载动态链接库时形成的。
动态链接库的命名规则:
-
Linux 操作系统:以 lib 作为前缀,以 .so 作为后缀,中间是库的名字,即:libxxx.so。
-
Windows 操作系统:以 lib 作为前缀,以 .dll 作为后缀,中间是库的名字,即:libxxx.dll。
生成动态链接库
生成动态链接库是使用的 gcc 命令。
-
-fPIC 或 -fpic: 使 gcc 生成的代码与位置无关,也就是使用相对位置。
-
-shared: 使编译器生成一个动态链接库。
生成动态链接库的具体步骤
1 | 1. 将源文件进行汇编操作,添加额外参数 -fpic/-fPIC |
动态链接库制作举例
使用上面制作静态链接库的源代码来制作动态链接库。
1 | 1. 将 .c 文件汇编成 .o 文件,额外的参数 -fpic/-fPIC |
动态链接库的使用
将动态链接库、头文件和测试程序放到一个目录中准备进行测试。
1 | 编译时,需要指定动态链接库的相关信息:库的路径 -L,库的名字 -l |
库的工作原理
-
静态链接库在链接阶段被打包到可执行程序中,当可执行程序被执行,静态链接库中的代码会一并加载到内存中。
-
动态链接库虽然链接阶段也指定了库路径和库名字,但是动态链接库并没有被打包到可执行程序中,只是检查了一下库文件是否存在和在可执行程序中记录了一下库的名字。程序执行的时候会先检测需要的动态链接库是否可以被加载。当动态链接库中函数被调用了,这时动态链接库才被加载到内存,如果不调用则不加载。动态链接库的检测和内存加载等操作都是由动态链接器来完成的。
动态链接器
动态链接器是一个独立于应用程序的进程,属于操作系统,它内部有一个动态链接库的搜索顺序。优先级从高到低分别是:
-
可执行文件内部的 DT_RPATH 段
-
系统的环境变量 LD_LIBRARY_PATH
-
系统动态链接库的缓存文件 /etc/ld.so.cache
-
存储动态链接库 / 静态库的系统目录 /lib/,/usr/lib/ 等
加载动态链接库的解决方案
方案 1 : 将动态链接库的路径添加到环境变量 LD_LIBRARY_PATH 中
-
配置文件
-
用户级别:~/.bashrc,对当前用户有效
-
系统级别:/etc/profile,设置对所有用户有效
-
-
在配置文件的最后添加
1 | export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:动态库的绝对路径 |
-
配置文件生效
-
修改了用户级别的配置文件,关闭当前终端,重新打开一个新终端就能生效了
-
修改了系统级别的配置文件,注销或者关闭系统,再开机配置就能生效了
-
也可以执行下面的命令让配置文件被重新加载
1
2
3
4
5
6source 简写 .,会让文件内容被重新加载
source ~/.bashrc
source /etc/profile
. ~/.bashrc
. /etc/profile -
方案 2 :更新 /etc/ld.so.cache 文件
-
找到动态链接库的绝对路径(不包括库的名字)
-
修改 /etc/ld.so.conf 文件,添加动态链接库的绝对路径(不包括库的名字),独占一行
-
更新 /etc/ld.so.conf 文件中的数据到 /etc/ld.so.cache 文件中
1 | sudo ldconfig |
方案 3 :拷贝动态链接库文件到系统库目录 /lib/ 或者 /usr/lib/ 中,也可以将动态链接库的软链接文件放进去
1 | 库拷贝 |
验证:ldd 命令可以检测程序是否能够通过动态链接器加载到对应的动态链接库
1 | ldd 可执行程序的名字 |
静态链接库的优缺点
-
优点:
-
静态链接库被打包到应用程序中,加载速度快
-
发布程序无需提供静态链接库,移植方便
-
-
缺点
-
相同的库文件可能在内存中被加载多份,浪费内存
-
库文件更新需要重新编译项目文件,浪费时间
-
动态链接库的优缺点
-
优点:
-
可以实现不同进程间的资源共享,动态链接库在内存中只存在一份拷贝,避免了静态链接库的浪费内存的问题
-
动态链接库升级简单,只需要替换库文件,无需重新编译项目文件
-
可以控制加载动态链接库的时机,不调用库函数动态链接库不会被加载
-
-
缺点:
-
加载速度比静态链接库慢,现代计算机的性能可以忽略不计
-
发布程序需要提供依赖的动态链接库
-
cc 和 gcc
cc 是来自 Unix 操作系统的 c 语言编译器,是 c compiler 的缩写。gcc 是来自 Linux 操作系统,是 GNU compiler collection 的缩写,它是一个编译器集合。
在 Linux 操作系统,cc 是 gcc 的一个软链接。
1 | (base) lyfubuntu@lyfubuntu:~$ which cc |
注:这样的主要原因是 Unix 操作系统是付费系统,这样做能够保证 makefile 在两个系统能兼容。下面就开始介绍 makefile 了。
Makefile
make 是一个命令工具,是一个解释 makefile 中指令的命令工具,makefile 定义了整个工程项目文件的编译规则,实现了”自动化编译“。当 makefile 编写完成后,只需要运行 make 命令,整个工程将完全自动编译,极大的提高了软件开发效率。
makefile 文件名可以命名为 makefile 和 Makefile 两种方式。构建项目的时候在哪个目录下执行构建命令 make ,这个目录下的 makefile 文件就会被加载。一个项目中可以有很多个位于不同目录的 makefile 文件。
规则
makefile 是由规则构成的,make 命令其实就是通过解析 makefile 的规则并运行它们实现自动化编译工作的。
注意:Makefile 中的缩进是制表符而不是空格符。1 | # 规则的语法格式: |
每条规则由三个部分组成:目标(target),依赖(depend)和命令(command)。
-
命令(command):规则需要执行的动作。
-
如:编译,进入目录等 shell 命令。
-
动作可以有多个,每条命令前必须有有一个 Tab 缩进并且独占一行。
-
-
依赖(depend):规则所必需的依赖条件。
-
如:生成可执行程序的目标文件。
-
如果规则的命令不需要任何依赖,那么规则的依赖可以为空。
-
当前规则中的依赖可以是其他规则中的目标,这样就形成了规则间的嵌套。
-
依赖可以有多个。
-
-
目标(target):
-
通过规则中的命令,可以生成一个和目标同名的文件。
-
命令可以有多个,因此目标也可以有多个。
-
可以只执行动作,不生成目标,这样的目标被称为伪目标。
-
1 | # 源文件 a.c b.c c.c ,头文件 head.h,生成的可执行程序 app |
规则的执行
make 命令编译程序的时候,首先找到 makefile 文件中的第一个规则,分析并执行相关动作。如果该动作的依赖不存在,这个动作就不会被执行。因此可以通过添加新的规则,将这个依赖生成出来。当第一个规则的所有依赖都已经生成出来了,这时第一条规则将被执行生成对应的目标,这时 make 命令任务就完成了。
1 | # 规则之间的嵌套 |
上面的例子中由于第一条规则的依赖不存在,因此需要先执行第二、第三、第四条规则生成第一条规则的依赖,当第一条规则的依赖全部生成,这时将执行第一条规则,然后 make 命令执行完毕。
如果想要执行 makefile 中的非第一条规则,需要执行 make 想要执行的规则的目标,如执行上面例子的第三条规则,需要执行 make b.o
文件的时间辍
make 命令会根据文件的时间戳判定是否执行 makefile 中相关规则的命令。
-
当目标时间戳 > 所有依赖的时间戳,这时 make 命令将不会执行这条规则。
-
当目标时间戳 < 某些依赖的时间戳,这时 make 命令将会执行这条规则。
-
当规则中目标文件不存在,那么 make 会执行这条规则。
1 | # 规则之间的嵌套 |
上面例子中,当执行过一次 make 命令后,修改 a.c 文件,这时再通过 make 命令编译项目,会先执行规则 2 更新目标文件 a.o,然后执行规则 1 更新目标文件 app,其余规则是不会被执行。
自动推导
make 是一个功能强大的构建工具,它有自动推导的能力,不会完全依赖 makefile。如果 makefile 没有指出编译规则,make 会自动使用 cc -c 命令来编译 .c 源文件。makefile 只需要给出需要构建的目标文件名(.o 文件),make 会自动为这个 .o 文件寻找合适的依赖文件(对应的 .c 文件),使用 cc -c 命令来构建这个目标文件。
1 | # 目录中有 add.c div.c head.h main.c makefile mult.c sub.c 这几个文件 |
1 | make |
上面中的例子中,目录中并没有 .o 文件,也不存在其他规则生成 .o 文件。但是 make 会使用默认的构造规则生成这些依赖文件,最终生成目标文件 calc。
自定义变量
makefile 用户可以自定义变量,这些变量是没有类型的。创建一个变量的时候一定要给它赋值。
1 | # 创建一个变量名并且给其赋值 |
1 | # 普通写法 |
预定义变量
makefile 中有一些预定义变量,用户可以直接使用这些变量。
常用的预定义变量
| 变量名 | 含义 | 默认值 |
|---|---|---|
| AR | 生成静态链接库的程序名称 | ar |
| AS | 汇编编译器的名称 | as |
| CC | C 语言编译器的名称 | cc |
| CPP | C 语言预编译器的名称 | $(CC) -E |
| CXX | C++ 语言编译器的名称 | g++ |
| FC | FORTRAN 语言编译器的名称 | f77 |
| RM | 删除文件程序的名称 | rm -f |
| ARFLAGS | 生成静态链接库的选项 | 无 |
| ASFLAGS | 汇编语言编译器的编译选项 | 无 |
| CFLAGS | C 语言编译器的编译选项 | 无 |
| CPPFLAGS | C 语言预编译器的编译选项 | 无 |
| CXXFLAGS | C++ 语言编译器的编译选项 | 无 |
| FFLAGS | FORTRAN 语言编译器的编译选项 | 无 |
1 | # 普通写法 |
自动变量
自动变量用来代表规则中的目标文件和依赖文件,只能再规则的命令中使用。
常见的自动变量
| 变量 | 含义 |
|---|---|
| $* | 表示目标文件的名称,不包含目标文件的扩展名 |
| $+ | 表示所有的依赖文件,依赖文件之间以空格分开,按照出现的先后顺序,可能包含重复的依赖文件 |
| $< | 依赖项中第一个依赖文件的名称 |
| $? | 依赖项中,所有比目标文件时间戳晚的依赖文件,依赖文件之间以空格分开 |
| $@ | 表示目标文件的名称,包含文件扩展名 |
| $^ | 依赖项中,所有不重复的依赖文件,以空格分开 |
1 | # 普通写法 |
模式匹配
1 | calc:add.o div.o main.o mult.o sub.o |
可以将上面例子中第二条规则到第六条规则改写成模板,使得 makefile 变得精简。
1 | # % 是一个通配符,匹配的是文件名 |
wildcard 函数
makefile 有很多函数,并且所有的函数都是有返回值的。函数的格式为 `$(函数名 参数1,参数2,参数3,…)。
wildcard 函数:获取指定目录下指定类型的文件名,返回值:以空格分隔、指定目录下的所有符合条件的文件名列表。
1 | # 该函数的参数只有一个,但是这个参数可以包含若干部分,以空格分隔 |
-
PATTERN: 某个或多个目录下的某种类型的文件,如当前目录下的 .c 文件可以写成 *.c。
-
可以指定多个路径,每个路径之间以空格分隔。
-
返回值:得到若干个文件的文件列表,文件名使用空格分隔
1 | src=$(wildcard *.c ./sub/*.c) |
patsubst 函数
作用:按照指定的模式替换指定的文件名的后缀。
1 | $(patsubst pattern,replacement,text) |
-
pattern:指定要被替换的文件名中的后缀,文件名和路径不需要设置,使用 % 表示,需要指定出要被替换的后缀,如 %.c。
-
replacement:指定出替换成的后缀,依旧使用 % 表示,需要指定出替换成的后缀,如 %.o。
-
text:被替换的原始文件名。
-
返回值:替换完成的文件名字符串。
1 | src=a.cpp b.cpp c.cpp d.cpp |
makefile 的编写
当前目录中有下面一些文件:add.c, div.c, head.h, main.c, mult.c, sub.c。
version 1
1 | calc:add.c div.c main.c mult.c sub.c |
缺点:某一个源文件被修改,所有的源文件都需要重新编译。
version 2
1 | calc:add.o div.o main.o mult.o sub.o |
缺点:规则冗余,需要精简。
version 3
1 | obj=add.o div.o main.o mult.o sub.o |
缺点:obj 值需要手动写出来。
version 4
1 | src=$(wildcard *.c) |
缺点:没有删除功能。
version 5
1 | src=$(wildcard *.c) |
1 | 删除 .o 文件和可执行程序 |
缺点:当执行完 make 命令后,向目录中新建一个 clean 文件,这时根据 make 关于文件时间戳的更新规则,无法通过 make clean 命令删除 .o 文件和可执行程序文件文件。
version 6
make 命令不会对伪目标进行文件时间戳检测,相应规则中的命令每次都会被执行。
伪目标的语法:.PHONY:伪文件名称。
1 | src=$(wildcard *.c) |
练习
1 | 目录结构 |
1 | target=app |
GDB 调试
gdb 是由 GNU 软件系统社区提供的调试器,和 gcc 配套组成了一套完整的开发环境,支持并移植到各种类 Unix 系统与 Windows 系统里的 MinGW 和 Cygwin。gcc/gdb 是 Linux 操作系统和许多类 Unix 操作系统的标准开发环境。
gdb 的吉祥物是射手鱼。
For a fish, the archer fish is known to shoot down bugs from low hanging plants by spitting water at them.
GDB 是一套字符界面的程序集,可以使用命令 gdb 加载要调试的程序。
调试准备
C 程序用 gcc 编译,C++ 程序用 g++ 编译。
-
-g: 在可执行文件中加入源代码的信息,但并不是把源文件嵌入到可执行程序中,因此调试时,需要保证 gdb 能找到源文件。
-
-O0: 可选,关闭编译器的优化选项。
-
-Wall: 打印所有 warning。
1 | 源文件 main.c |
启动 gdb
gdb 是一个用于应用程序调试的进程,gdb 启动后,被调试的应用程序是没有执行的。
1 | gdb 可执行程序的名字 |
命令行传参
1 | // main.c |
1 | gcc main.c -o app -g |
gdb 中启动程序
在整个 gdb 调试过程中,启动应用程序的命令只能使用一次。
-
run: 启动程序,缩写为 r,如果程序中设置了断点,会停在第一个断点的位置,如果没有设置断点,程序将执行完毕。
-
start:启动程序,会阻塞在 main 函数的第一行。
1 | 方式 1 |
1 | 继续运行 |
退出 gdb
1 | quit = q |
当前文件查看代码
默认 main 函数所在的文件为当前文件。
1 | 查看代码 |
可以继续执行 list 命令来继续查看后边的内容,也可以直接按 Enter 键(等价于执行上一次执行的那个 gdb 命令)。
切换文件查看代码
执行完切换命令之后,相应的文件就变成了当前文件。
1 | 切换到指定的文件,并显示这行号对应的上下文代码,默认情况下只显示 10 行内容 |
设置显示的行数
1 | listsize 缩写: list |
设置断点
-
常规断点:程序运行到断点位置会被阻塞。
-
条件断点:只有指定的条件被满足了程序才会在断点处阻塞。
1 | 设置普通断点在当前文件 |
查看断点
1 | info = i |
-
Num: 断点的编号,删除断点和设置断点状态的时候需要使用。
-
Enb: 当前断点的状态,y 表示断点可用,n 表示断点不可用。
-
What: 描述断点被设置在哪个文件的哪行或者哪个函数上。
删除断点
1 | delete = del = d |
设置断点状态
1 | 断点失效后,gdb 调试过程中程序是不会停在这个位置的 |
继续运行 gdb
1 | continue = c |
打印变量值
打印命令为 print,格式化输出字符如下表:
| 格式化字符(/fmt) | 说明 |
|---|---|
| /x | 十六进制形式打印整数 |
| /d | 有符号、十进制形式打印整数 |
| /u | 无符号、十进制形式打印整数 |
| /o | 八进制打印整数 |
| /t | 二进制打印整数 |
| /f | 浮点数形式打印变量或者表达式的值 |
| /c | 字符形式打印变量或者表达式的值 |
1 | print = p |
打印变量类型
1 | (gdb) ptype 变量名 |
设置变量名的自动显示
1 | (gdb) display 变量名 |
查看自动显示列表
1 | info == i |
-
Num: 变量或表达式的编号。
-
Enb: 表示当前变量或表达式的状态。y 表示值会被打印,n 表示值不会被打印。
-
Expression: 被自动打印值的变量或表达式的名字。
取消自动显示
1 | 删除自动显示列表中的变量或表达式 |
step
step 命令每次执行一次,程序将执行一行,如果这一行是一个函数调用,程序将会进入到函数内部。
1 | step = s |
finish
跳出函数体,前提:函数体内不能有有效断点。
1 | (gdb) finish |
next
next 命令和 step 命令功能相似,next 命令不会进入到函数内部。
1 | next = n |
until
跳出循环体,前提:
-
循环体内不能有有效断点。
-
必须在循环体的开始/结束行执行 until 命令。
1 | (gdb) until |
设置变量值
1 | (gdb) set var 变量名=值 |
结语
第十篇博文写完,开心!!!!
今天,也是充满希望的一天。
 wechat
wechat alipay
alipay




.png)





