官方文章 · 发布日期:2025年3月20日
src: https://www.anthropic.com/engineering/claude-think-tool
导语
扩展思考能力自首次发布以来已有所改进,因此我们建议在大多数情况下使用扩展思考功能,而非专用的”思考”工具。扩展思考提供了类似的益处——为 Claude 提供空间来推理复杂问题——且集成度和性能更佳。请参阅我们的扩展思考文档了解实现细节。
在我们持续增强 Claude 复杂问题解决能力的过程中,我们发现了一种特别有效的方法:”思考”工具,它为 Claude 在复杂任务中创建了专用的结构化思考空间。
这种简单而强大的技术——正如我们将在下文中解释的,它与 Claude 新的”扩展思考”能力不同(请参阅此处了解扩展思考的实现细节)——在 Claude 的代理式工具使用能力方面取得了显著改善。这包括遵循策略、做出一致决策以及处理多步骤问题,且实现开销极小。
在这篇文章中,我们将探讨如何在不同应用中实现”思考”工具,并基于经过验证的基准测试结果分享针对开发者的实用指导。
“思考”工具是什么?
通过”思考”工具,我们赋予 Claude 在得出最终答案的过程中包含一个额外的思考步骤的能力——这个步骤拥有自己专属的思考空间。
虽然听起来与扩展思考类似,但它是一个不同的概念。扩展思考是指 Claude 在开始生成回复之前进行的深度思考和规划迭代。而”思考”工具则是指 Claude 在开始生成回复之后,添加一个步骤来停下来思考是否拥有继续推进所需的所有信息。这对于执行长链条的工具调用或与用户进行长多步骤对话时特别有帮助。
这使得”思考”工具更适合 Claude 无法仅从用户查询中获得所有需要的信息来形成回复,以及需要处理外部信息(例如工具调用结果中的信息)的情况。通过”思考”工具进行的推理不如扩展思考那么全面,而是更专注于模型发现的新信息。
我们建议在以下场景使用扩展思考:
- 更简单的工具使用场景,如非顺序工具调用或直接的指令遵循
- 不需要 Claude 调用工具的场景,如编程、数学和物理问题
“思考”工具更适合:
- Claude 需要调用复杂工具时
- 需要在长链条工具调用中仔细分析工具输出时
- 在包含详细指南的政策密集型环境中导航时
- 在顺序决策中,每个步骤都建立在先前步骤之上且错误成本高昂时
以下是使用标准工具规范格式的示例实现,来自 τ-Bench:
{
"name": "think",
"description": "使用此工具进行思考。它不会获取新信息或更改数据库,只是将思考内容追加到日志中。当需要复杂推理或某种缓存记忆时使用。",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "要思考的内容。"
}
},
"required": ["thought"]
}
}τ-Bench 上的表现
我们使用 τ-bench(tau-bench)评估了”思考”工具。这是一个综合基准测试,旨在测试模型在真实客户服务场景中使用工具的能力,其中”思考”工具是评估标准环境的一部分。
τ-bench 评估 Claude 在以下方面的能力:
- 与模拟用户进行真实对话
- 一致地遵循复杂的客户服务代理策略指南
- 使用各种工具访问和操作环境数据库
τ-bench 中使用的主要评估指标是 pass^k,它衡量所有 k 个独立任务试验都成功的概率,并在所有任务中取平均值。与其他 LLM 评估中常用的 pass@k 指标(衡量 k 次试验中至少一次成功)不同,pass^k 评估一致性和可靠性——这是客户服务应用中的关键品质,因为一致地遵守策略至关重要。
性能分析
我们的评估比较了几种不同的配置:
- 基线(无”思考”工具,无扩展思考模式)
- 仅扩展思考模式
- 仅”思考”工具
- “思考”工具配合优化提示(针对航空领域)
结果显示,当 Claude 3.7 在基准测试的”航空”和”零售”客户服务领域有效使用”思考”工具时,表现显著提升:
- 航空领域:配备优化提示的”思考”工具在 pass^1 指标上达到 0.570,而基线仅为 0.370——相对提升 54%;
- 零售领域:仅”思考”工具就达到 0.812,而基线为 0.783。
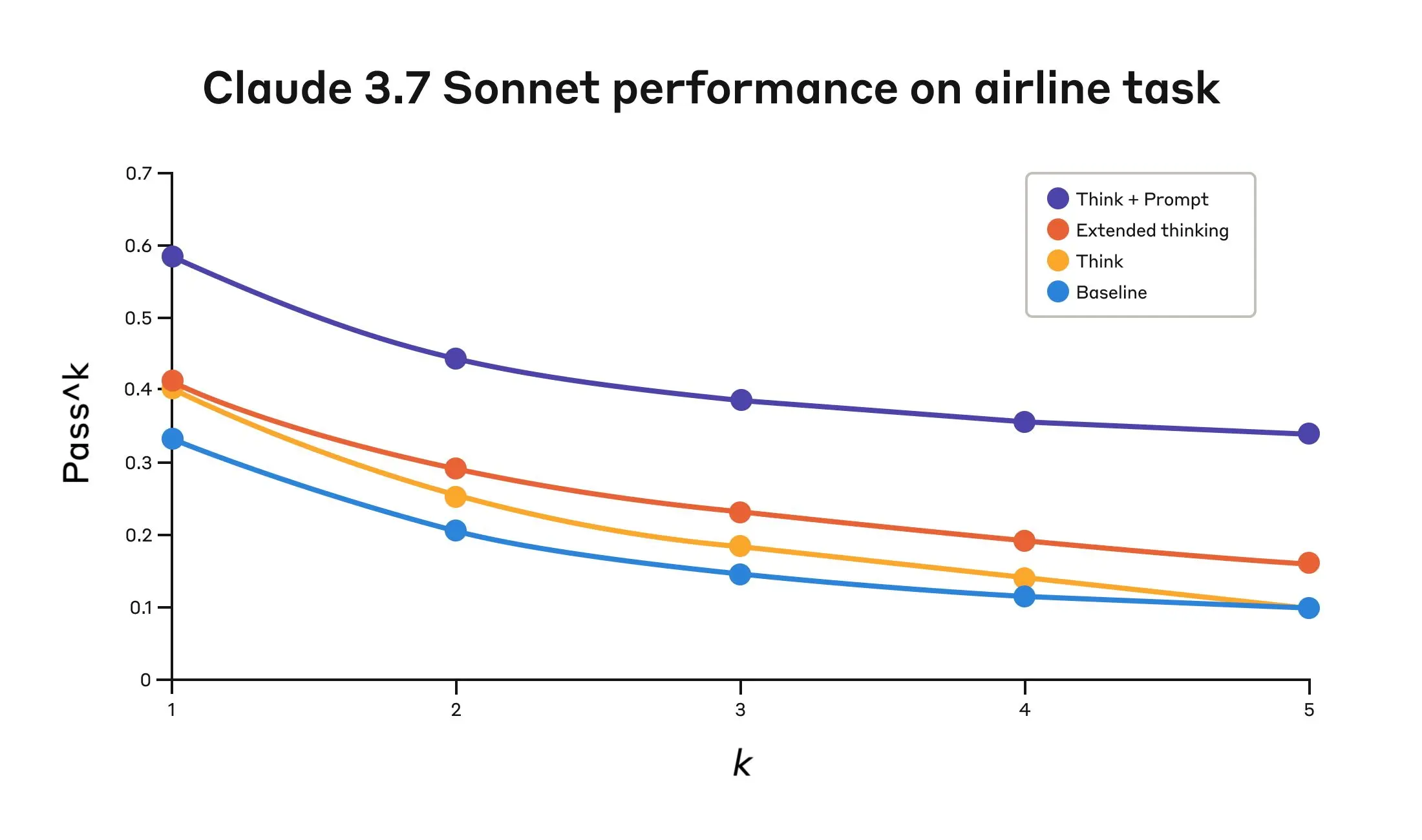
Claude 3.7 Sonnet 在 Tau-Bench 评估的”航空”领域表现
| 配置 | k = 1 | k = 2 | k = 3 | k = 4 | k = 5 |
|---|---|---|---|---|---|
| “思考” + 提示 | 0.584 | 0.444 | 0.384 | 0.356 | 0.340 |
| “思考” | 0.404 | 0.254 | 0.186 | 0.140 | 0.100 |
| 扩展思考 | 0.412 | 0.290 | 0.232 | 0.192 | 0.160 |
| 基线 | 0.332 | 0.206 | 0.148 | 0.116 | 0.100 |
四种不同配置的评估结果。分数为比例值。
航空领域中最好的表现是通过将”思考”工具与优化提示结合实现的,该提示提供了分析客户请求时应使用的推理方法示例。以下是优化提示的示例:
## 使用思考工具
在收到工具结果后采取任何行动或回复用户之前,使用思考工具作为草稿纸来:
- 列出适用于当前请求的具体规则
- 检查是否已收集所有必需信息
- 验证计划的操作是否符合所有政策
- 迭代检查工具结果的正确性
以下是在思考工具中应迭代检查的内容示例:
<think_tool_example_1>
用户想取消航班 ABC123
- 需要验证:用户 ID、预订 ID、原因
- 检查取消规则:
* 是否在预订后 24 小时内?
* 如果不是,检查机票等级和保险
- 验证没有已飞行或在过去的航段
- 计划:收集缺失信息、验证规则、获取确认
</think_tool_example_1>
<think_tool_example_2>
用户想预订 3 张去纽约的机票,每人 2 件托运行李
- 需要用户 ID 来检查:
* 会员等级以确定行李额度
* 个人资料中存在的付款方式
- 行李计算:
* 经济舱 × 3 名乘客
* 如果普通会员:每人 1 件免费行李 → 3 件额外行李 = $150
* 如果银卡会员:每人 2 件免费行李 → 0 件额外行李 = $0
* 如果金卡会员:每人 3 件免费行李 → 0 件额外行李 = $0
- 需要验证的付款规则:
* 最多 1 张旅行券、1 张信用卡、3 张礼品卡
* 所有付款方式必须在个人资料中
* 旅行券余额将作废
- 计划:
1. 获取用户 ID
2. 验证会员等级以确定行李费
3. 检查个人资料中的付款方式及其组合是否被允许
4. 计算总额:机票价格 + 任何行李费
5. 获取预订的明确确认
</think_tool_example_2>特别有趣的是不同方法的比较结果。使用配备优化提示的”思考”工具比扩展思考模式取得了显著更好的结果(后者与未加提示的”思考”工具表现相似)。仅使用”思考”工具(无提示)比基线有所改善,但仍低于优化方法。
“思考”工具与优化提示的组合以显著优势提供了最强的性能,这可能归因于基准测试中航空政策部分的高度复杂性,模型从获得如何”思考”的示例中受益最大。
在零售领域,我们还测试了各种配置以了解每种方法的具体影响。
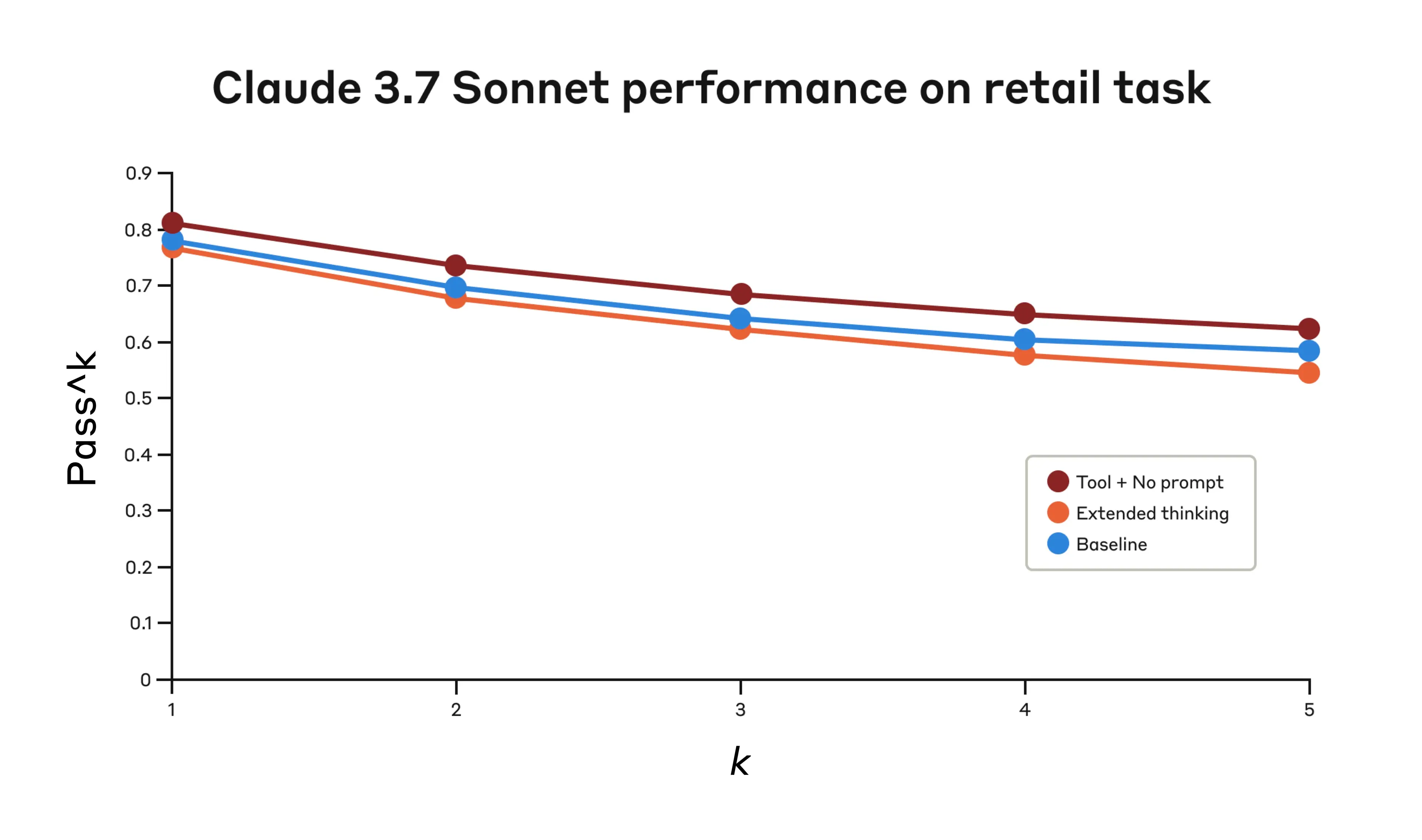
Claude 3.7 Sonnet 在 Tau-Bench 评估的”零售”领域表现
| 配置 | k = 1 | k = 2 | k = 3 | k = 4 | k = 5 |
|---|---|---|---|---|---|
| “思考” + 无提示 | 0.812 | 0.735 | 0.685 | 0.650 | 0.626 |
| 扩展思考 | 0.770 | 0.681 | 0.623 | 0.581 | 0.548 |
| 基线 | 0.783 | 0.695 | 0.643 | 0.607 | 0.583 |
三种不同配置的评估结果。分数为比例值。
“思考”工具即使没有额外提示也达到了最高的 pass^1 分数 0.812。零售政策明显比航空领域更容易导航,Claude 仅凭拥有思考空间就能改进,无需进一步指导。
τ-Bench 分析的关键见解
我们的详细分析揭示了有助于有效实施”思考”工具的几个模式:
- 提示在困难领域至关重要。仅仅提供”思考”工具可能会在一定程度上提升性能,但将其与优化提示配对在困难领域会产生显著更好的结果。然而,较简单的领域可能仅从拥有”思考”空间就能受益。
- 跨试验的一致性改善。使用”思考”带来的改进在 pass^k 中一直保持到 k=5,表明该工具帮助 Claude 更有效地处理边缘案例和异常场景。
SWE-Bench 上的表现
在评估 Claude 3.7 Sonnet 时,我们在 SWE-bench 设置中添加了类似的”思考”工具,为取得的 0.623 的最先进分数做出了贡献。调整后的”思考”工具定义如下:
{
"name": "think",
"description": "使用此工具进行思考。它不会获取新信息或对仓库进行任何更改,只是记录思考内容。当需要复杂推理或头脑风暴时使用。例如,如果你探索仓库并发现了错误的来源,调用此工具来头脑风暴几种修复错误的独特方法,并评估哪些更改可能是最简单和最有效的。或者,如果你收到一些测试结果,调用此工具来头脑风暴修复失败测试的方法。",
"input_schema": {
"type": "object",
"properties": {
"thought": {
"type": "string",
"description": "你的思考。"
}
},
"required": ["thought"]
}
}我们的实验(n=30 个使用”思考”工具的样本,n=144 个不使用的样本)显示,包含此工具使性能平均提高了 1.6%(Welch’s t 检验:t(38.89) = 6.71, p < .001, d = 1.47)。
何时使用”思考”工具
基于这些评估结果,我们确定了 Claude 最能从”思考”工具中受益的具体场景:
- 工具输出分析。当 Claude 需要在行动前仔细处理先前工具调用的输出,并且可能需要回溯其方法时;
- 政策密集型环境。当 Claude 需要遵循详细指南并验证合规性时;
- 顺序决策。当每个动作都建立在先前的动作之上且错误成本高昂时(常见于多步骤领域)。
实施最佳实践
为了充分利用 Claude 的”思考”工具,我们基于 τ-bench 实验推荐以下实施实践。
1. 使用领域特定示例进行策略性提示
最有效的方法是提供关于何时以及如何使用”思考”工具的清晰说明,如 τ-bench 航空领域所使用的。提供针对您特定用例的示例能显著提高模型使用”思考”工具的效果:
- 推理过程中期望的详细程度;
- 如何将复杂指令分解为可操作的步骤;
- 处理常见场景的决策树;
- 如何检查是否已收集所有必要信息。
2. 将复杂指导放在系统提示中
我们发现,当”思考”工具的说明较长和/或复杂时,将其包含在系统提示中比放在工具描述本身中更有效。这种方法提供了更广泛的上下文,帮助模型更好地将思考过程整合到其整体行为中。
何时不使用”思考”工具
虽然”思考”工具可以提供实质性改进,但它并不适用于所有工具使用场景,且确实会增加提示长度和输出令牌的成本。具体而言,我们发现在以下使用案例中,”思考”工具不会带来任何改进:
- 非顺序工具调用。如果 Claude 只需要完成一次工具调用或多次并行调用来完成任务,添加”思考”不太可能带来任何改进。
- 简单指令遵循。当 Claude 不需要遵守太多约束,且其默认行为已经足够好时,额外的”思考”不太可能带来收益。
开始使用
“思考”工具是添加到 Claude 实现中的一个简单补充,可以在几个步骤内产生有意义的改进:
- 在代理式工具使用场景中测试。从具有挑战性的用例开始——即 Claude 目前在政策遵守或长工具调用链中的复杂推理方面存在困难的用例。
- 添加工具定义。实现针对您领域的”思考”工具。它只需要最少的代码,但支持更有结构的推理。同时考虑在系统提示中包含关于何时以及如何使用该工具的说明,并提供与您领域相关的示例。
- 监控和优化。观察 Claude 在实践中如何使用该工具,并调整您的提示以鼓励更有效的思考模式。
最好的部分是,添加此工具在性能结果方面几乎没有负面影响。除非 Claude 决定使用它,否则它不会改变外部行为,也不会干扰您现有的工具或工作流程。
结论
我们的研究表明,”思考”工具可以显著增强 Claude 3.7 Sonnet 在需要政策遵守和长工具调用链推理的复杂任务上的表现[1]。”思考”并非万能解决方案,但对于正确的用例,它提供了实质性的益处,且实现复杂性极低。
我们期待看到您如何使用”思考”工具构建更强大、更可靠、更透明的 Claude AI 系统。
[1] 虽然我们的 τ-Bench 结果专注于 Claude 3.7 Sonnet 配合”思考”工具的改进,但我们的实验表明,Claude 3.5 Sonnet(新版)也能通过相同的配置获得性能提升,表明这种改进也能推广到其他 Claude 模型。
结语
第三百七十二篇博文写完,开心!!!!
今天,也是充满希望的一天。



