前言
模型地址:https://huggingface.co/open-r1/OpenR1-Distill-7B

模型摘要
OpenR1-Distill-7B 是 Qwen/Qwen2.5-Math-7B 在“思维混合”(Mixture-of-Thoughts)数据集上进行后训练的版本。该数据集是一个精心整理的、包含 35 万条经过验证的推理轨迹的数据集,这些轨迹是从 DeepSeek-R1 模型中蒸馏提取的。该数据集涵盖了数学、编程和科学领域的任务,旨在教导语言模型进行逐步推理。
OpenR1-Distill-7B 复现了 deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 的推理能力,同时保持了完全的开放性和可复现性。它非常适用于关于推理时计算(inference-time compute)以及带有可验证奖励的强化学习(RLVR)的研究。
模型描述
- 模型类型:一个拥有 70 亿参数的类 GPT 模型,在公开可用与合成的混合数据集上进行了后训练。
- 语言:主要为英语
- 许可证:Apache 2.0
- 微调自模型:Qwen/Qwen2.5-Math-7B 的一个变体,该变体的 RoPE 基础频率被扩展至 300k,以支持在 32k token 上下文长度上的训练。
模型来源
- Repository: https://github.com/huggingface/open-r1
- Training logs: https://wandb.ai/huggingface/open-r1/runs/199cum6l
- Evaluation logs: https://huggingface.co/datasets/open-r1/details-open-r1_OpenR1-Distill-7B
用法
要与模型进行对话,请首先安装 🤗 Transformers:
pip install transformers>0.52然后,按如下方式运行聊天命令行界面:
transformers chat open-r1/OpenR1-Distill-7B \
max_new_tokens=2048 \
do_sample=True \
temperature=0.6 \
top_p=0.95或者,也可以使用 pipeline() 函数来运行该模型:
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="open-r1/OpenR1-Distill-7B", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{"role": "user", "content": "Which number is larger, 9.9 or 9.11?"},
]
outputs = pipe(messages, max_new_tokens=2048, do_sample=True, temperature=0.6, top_p=0.95, return_full_text=False)
print(outputs[0]["generated_text"])性能
我们使用 Lighteval 来在以下基准测试上评估模型:
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCodeBench v5 |
|---|---|---|---|---|
| OpenR1-Distill-7B | 52.7 | 89.0 | 52.8 | 39.4 |
| DeepSeek-R1-Distill-Qwen-7B | 51.3 | 93.5 | 52.4 | 37.4 |
所有分数均表示 pass@1 准确率,并使用了 温度=0.6 和 top_p=0.95 的采样参数。DeepSeek-R1 的技术报告采用对每个查询生成 4 到 64 个响应的方式来估算 pass@1,但并未针对每个基准测试指定具体的响应数量。在上表中,我们通过以下每个查询所对应的响应数量来估算 pass@1 准确率:
| Benchmark | Number of responses per query |
|---|---|
| AIME 2024 | 64 |
| MATH-500 | 4 |
| GPQA Diamond | 8 |
| LiveCodeBench | 16 |
请注意,对于像 AIME 2024 这样的基准测试,进行大量响应采样至关重要,因为它总共只有 30 道题目,这会导致在重复运行评估时产生很高的方差。每个提示需要采样多少次响应的选择,很可能解释了我们的评估结果与 DeepSeek 所报告结果之间的微小差异。请访问 open-r1 代码仓库以获取如何复现这些结果的说明。
训练方法论
OpenR1-Distill-7B 是通过在“思维混合”(Mixture-of-Thoughts)数据集上进行监督式微调来训练的。该数据集包含 35 万条从 DeepSeek-R1 中蒸馏出的推理轨迹。为了优化数据混合比例,我们遵循了 Phi-4-reasoning 技术报告中描述的相同方法论,即可以按领域独立地优化混合比例,然后再将它们组合成单一数据集。下图展示了我们在数学和代码领域进行实验的演进过程:
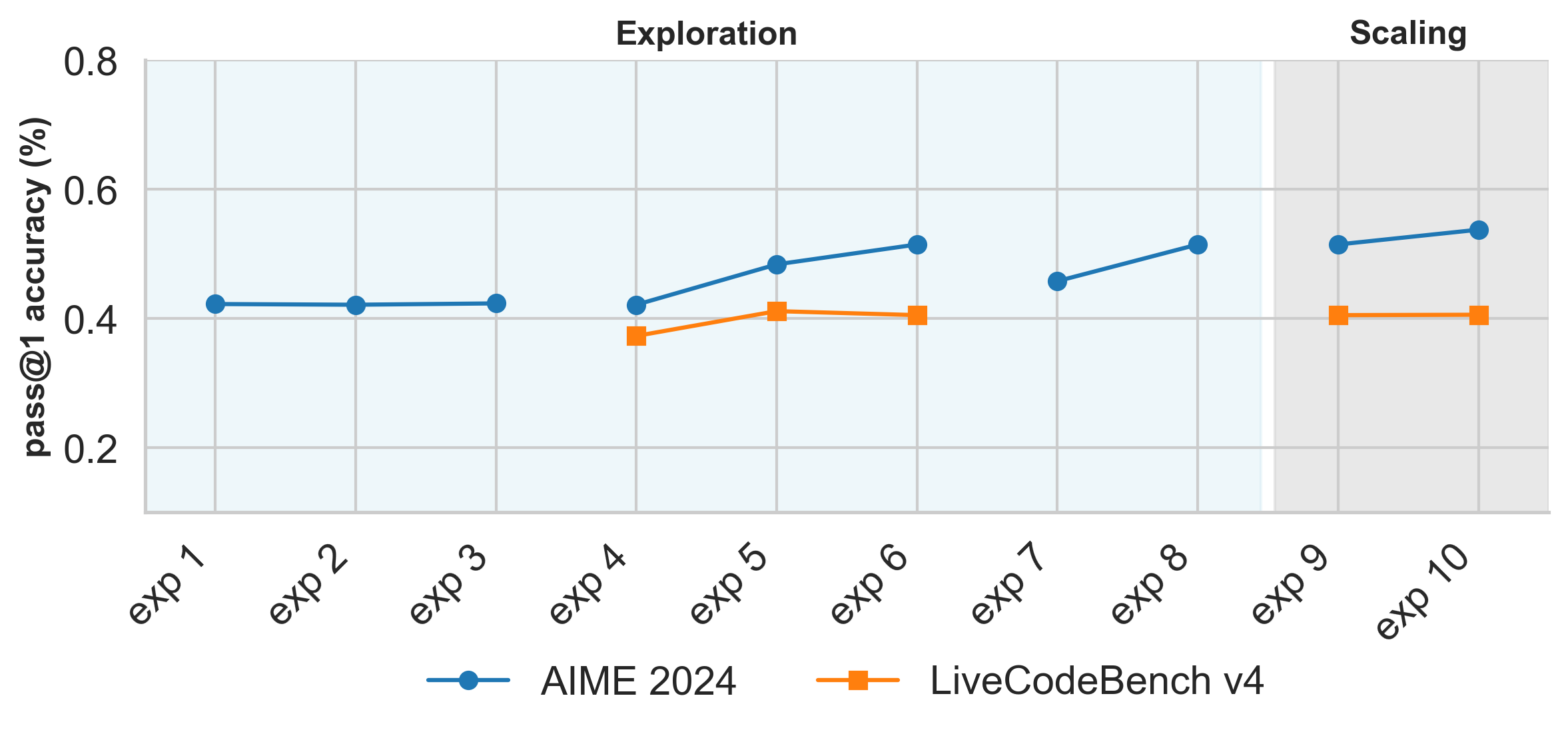
各个实验对应于以下内容:
实验 1 - 3 (exp1 - exp3): 分别将模型的 RoPE 基础频率从 10k 扩展到 100k、300k 和 500k。我们发现这些缩放因子之间没有显著差异,因此在所有后续实验中均使用了 300k。
实验 4 - 6 (exp4 - exp6): 分别将数学和代码混合数据集上的学习率从 1e-5 独立地缩放到 2e-5 和 4e-5。
实验 7 - 8 (exp7 - exp8): 在数学混合数据集上,衡量序列打包”的影响(实验 7)与不进行打包”的影响(实验 8)。
实验 9 - 10 (exp9 - exp10): 衡量在全部三种混合数据集(数学、代码和科学)上进行训练,与仅在数学和代码数据集上进行训练的影响。
在我们的消融实验中,我们使用 LiveCodeBench v4 来加速评估过程,因为它包含的问题数量大约是 v5 版本的一半,但仍然能够代表完整基准测试的水平。
训练超参数
训练期间使用了以下超参数:
- num_epochs: 5.0
- learning_rate: 4.0e-05
- num_devices: 8
- train_batch_size: 2
- gradient_accumulation_steps: 8
- total_train_batch_size: 2 * 8 * 8 = 128
- seed: 42
- distributed_type: DeepSpeed ZeRO-3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine_with_min_lr with min_lr_rate=0.1
- lr_scheduler_warmup_ratio: 0.03
- max_grad_norm: 0.2
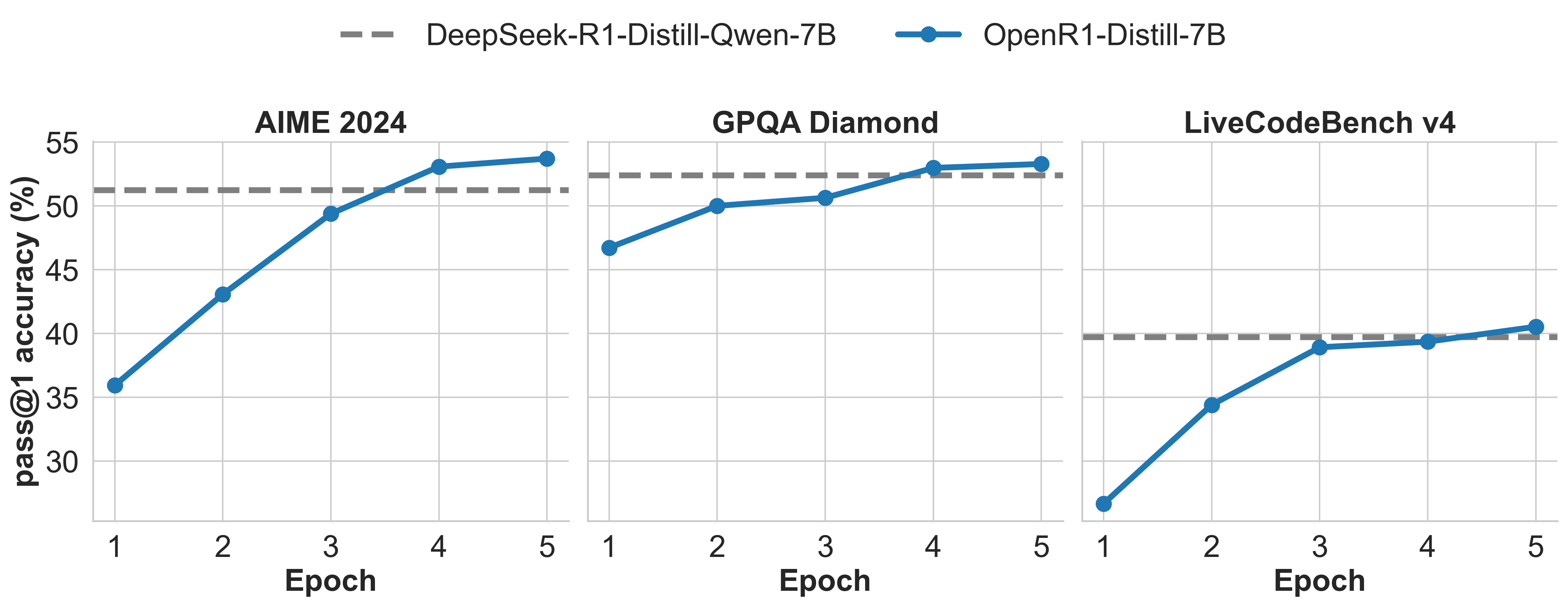
训练结果
在训练过程中,我们每个 epoch 都会在 AIME 2024、GPQA Diamond 和 LiveCodeBench v4 这三个基准上监控模型的进展。下图展示了训练结果:
框架版本
- Platform: Linux-5.15.0-1049-aws-x86_64-with-glibc2.31
- Python version: 3.11.11
- TRL version: 0.18.0.dev0
- PyTorch version: 2.6.0
- Transformers version: 4.52.0.dev0
- Accelerate version: 1.4.0
- Datasets version: 3.5.1
- HF Hub version: 0.30.2
- bitsandbytes version: 0.45.5
- DeepSpeed version: 0.16.8
- Liger-Kernel version: 0.5.9
- OpenAI version: 1.76.2
- vLLM version: 0.8.4
引用
如果您在自己的工作中发现该模型有用,请考虑按如下方式引用它:
@misc{openr1,
title = {Open R1: A fully open reproduction of DeepSeek-R1},
url = {https://github.com/huggingface/open-r1},
author = {Hugging Face},
month = {January},
year = {2025}
}结语
第三百五十六篇博文写完,开心!!!!
今天,也是充满希望的一天。



