前言
在这一部分,我们将探讨如何使用Transformer模型将长文档浓缩成摘要,这一任务被称为文本摘要。这是自然语言处理中最具挑战性的任务之一,因为它需要多种能力,如理解长篇文章并生成连贯的文本,抓住文档中的主要主题。然而,当做得好时,文本摘要是一个强大的工具,可以通过减轻领域专家的负担,让他们不必详细阅读长文档,从而加快各种业务流程。
尽管Hugging Face Hub上已经存在各种经过微调的摘要模型,但几乎所有这些模型都只适用于英语文档。因此,为了在这个部分增加一些新意,我们将训练一个英语和西班牙语的双语模型。到本部分结束时,你将拥有一个可以总结客户评论的模型,就像这里展示的那样:
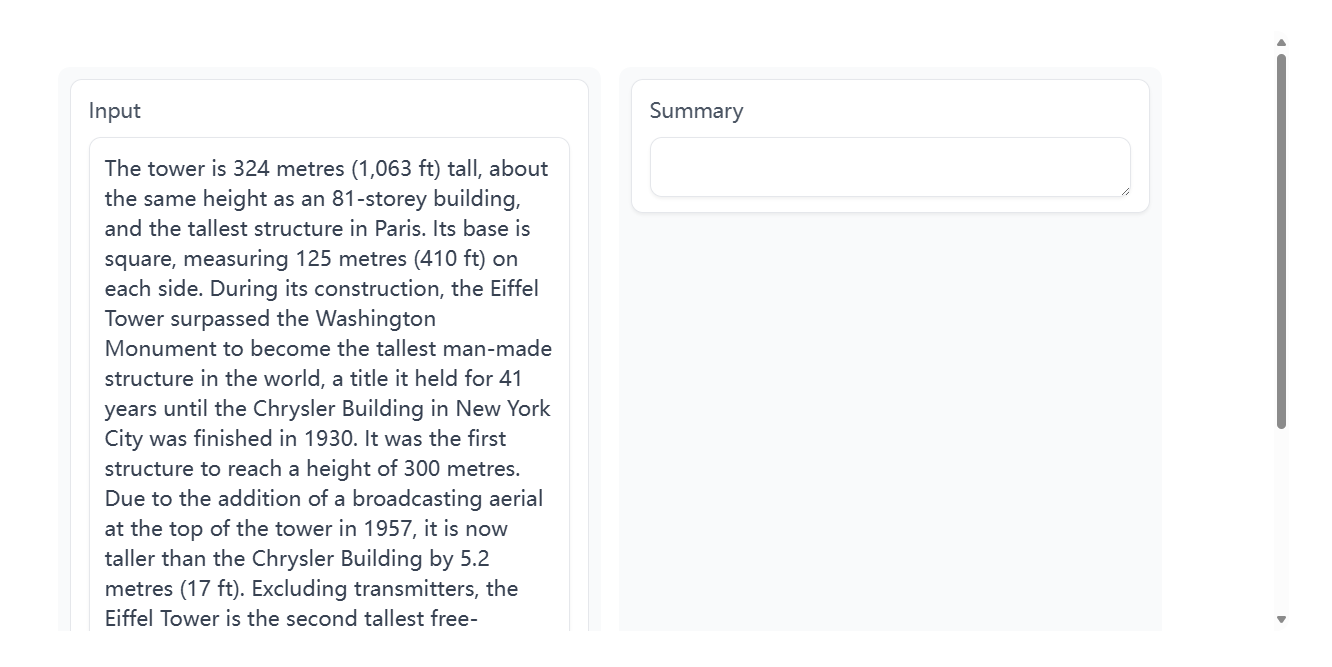
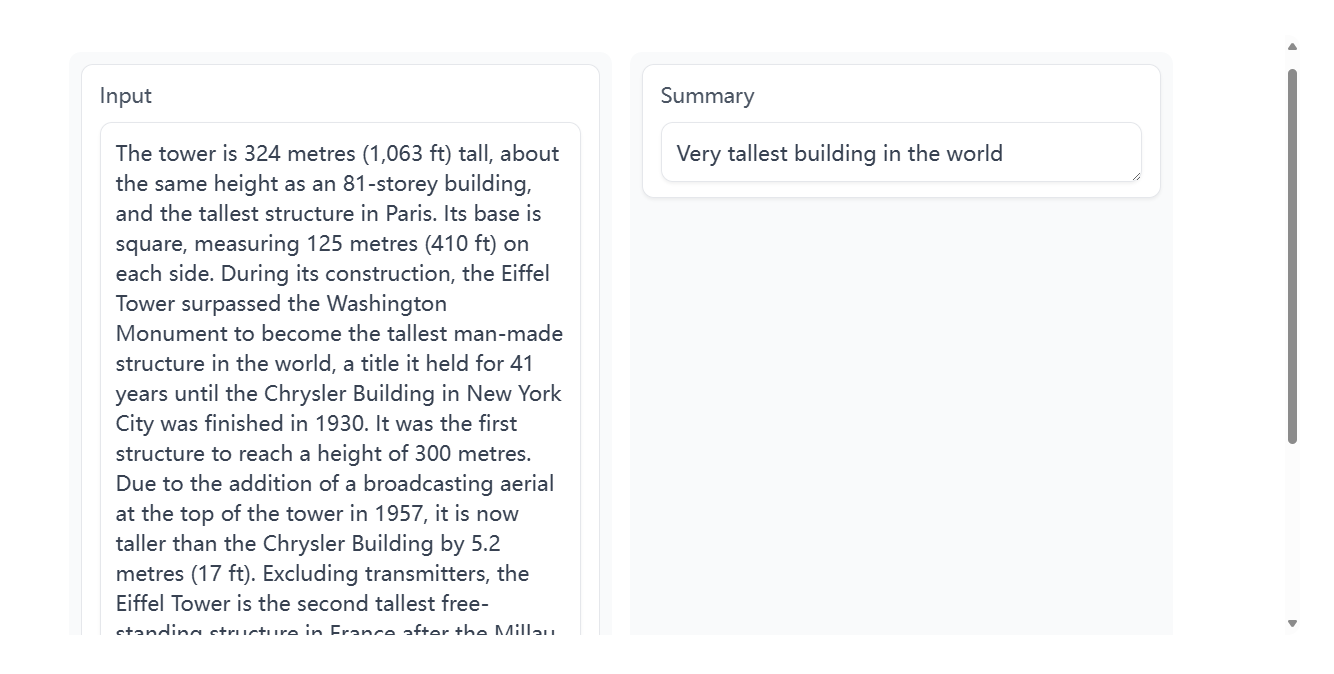
我们将看到,这些摘要之所以简洁,是因为它们是从客户在产品评论中提供的标题中学到的。让我们首先为这项任务收集一个合适的双语语料库。
src link: https://huggingface.co/learn/llm-course/chapter7/5
Operating System: Ubuntu 22.04.4 LTS
参考文档
准备多语言语料库
我们将使用多语言亚马逊评论语料库来创建我们的双语摘要器。这个语料库包含六种语言的亚马逊产品评论,通常用于多语言分类器的基准测试。然而,由于每条评论都附有一个简短的标题,我们可以将这些标题作为我们模型要学习的目标摘要!要开始使用,让我们从Hugging Face Hub下载英语和西班牙语的子集:
from datasets import load_dataset
spanish_dataset = load_dataset("amazon_reviews_multi", "es")
english_dataset = load_dataset("amazon_reviews_multi", "en")
english_datasetDatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})如你所见,对于每种语言,训练集有200,000条评论,验证集和测试集各有5,000条评论。我们感兴趣的评论信息包含在review_body和review_title列中。让我们通过创建一个简单的函数来查看一些示例,该函数从训练集中随机抽取样本,使用我们在第5章中学到的技术:
def show_samples(dataset, num_samples=3, seed=42):
sample = dataset["train"].shuffle(seed=seed).select(range(num_samples))
for example in sample:
print(f"\n'>> Title: {example['review_title']}'")
print(f"'>> Review: {example['review_body']}'")
show_samples(english_dataset)'>> Title: Worked in front position, not rear'
'>> Review: 3 stars because these are not rear brakes as stated in the item description. At least the mount adapter only worked on the front fork of the bike that I got it for.'
'>> Title: meh'
'>> Review: Does it’s job and it’s gorgeous but mine is falling apart, I had to basically put it together again with hot glue'
'>> Title: Can\'t beat these for the money'
'>> Review: Bought this for handling miscellaneous aircraft parts and hanger "stuff" that I needed to organize; it really fit the bill. The unit arrived quickly, was well packaged and arrived intact (always a good sign). There are five wall mounts-- three on the top and two on the bottom. I wanted to mount it on the wall, so all I had to do was to remove the top two layers of plastic drawers, as well as the bottom corner drawers, place it when I wanted and mark it; I then used some of the new plastic screw in wall anchors (the 50 pound variety) and it easily mounted to the wall. Some have remarked that they wanted dividers for the drawers, and that they made those. Good idea. My application was that I needed something that I can see the contents at about eye level, so I wanted the fuller-sized drawers. I also like that these are the new plastic that doesn\'t get brittle and split like my older plastic drawers did. I like the all-plastic construction. It\'s heavy duty enough to hold metal parts, but being made of plastic it\'s not as heavy as a metal frame, so you can easily mount it to the wall and still load it up with heavy stuff, or light stuff. No problem there. For the money, you can\'t beat it. Best one of these I\'ve bought to date-- and I\'ve been using some version of these for over forty years.'✏️ 试试看!在 Dataset.shuffle() 命令中更改随机种子,以探索语料库中的其他评论。如果你是西班牙语使用者,不妨看看 spanish_dataset 中的评论,看看标题是否也像是合理的摘要。
这个样本展示了网上常见的评论的多样性,从正面到负面(以及介于两者之间的各种评论!)。虽然“meh”标题的示例不太有用,但其他标题看起来像是对评论本身的不错的概括。在单个GPU上训练所有40万条评论的摘要模型需要花费太长时间,因此我们将专注于生成单个产品领域的摘要。为了了解我们可以选择哪些领域,让我们将english_dataset转换为pandas.DataFrame并计算每个产品类别的评论数量:
english_dataset.set_format("pandas")
english_df = english_dataset["train"][:]
# Show counts for top 20 products
english_df["product_category"].value_counts()[:20]home 17679
apparel 15951
wireless 15717
other 13418
beauty 12091
drugstore 11730
kitchen 10382
toy 8745
sports 8277
automotive 7506
lawn_and_garden 7327
home_improvement 7136
pet_products 7082
digital_ebook_purchase 6749
pc 6401
electronics 6186
office_product 5521
shoes 5197
grocery 4730
book 3756
Name: product_category, dtype: int64英语数据集中最受欢迎的产品是家居用品、服装和无线电子产品。不过,为了紧扣亚马逊的主题,让我们专注于总结书评——毕竟,这才是该公司成立的初衷!我们可以看到两个符合条件的产品类别(书籍和数字电子书购买),所以让我们过滤这两种语言的数据集,只保留这些产品。正如我们在第5章中看到的,Dataset.filter()函数允许我们非常高效地对数据集进行切片,所以我们可以定义一个简单的函数来完成这个任务:
def filter_books(example):
return (
example["product_category"] == "book"
or example["product_category"] == "digital_ebook_purchase"
)现在,当我们将这个函数应用到 english_dataset 和 spanish_dataset 时,结果将只包含那些涉及图书类别的行。在应用过滤器之前,让我们将 english_dataset 的格式从 “pandas” 改回 “arrow”:
english_dataset.reset_format()然后我们可以应用过滤器功能,作为一个安全检查,让我们检查一下评论的样本,看看它们是否确实是关于书籍的:
spanish_books = spanish_dataset.filter(filter_books)
english_books = english_dataset.filter(filter_books)
show_samples(english_books)'>> Title: I\'m dissapointed.'
'>> Review: I guess I had higher expectations for this book from the reviews. I really thought I\'d at least like it. The plot idea was great. I loved Ash but, it just didnt go anywhere. Most of the book was about their radio show and talking to callers. I wanted the author to dig deeper so we could really get to know the characters. All we know about Grace is that she is attractive looking, Latino and is kind of a brat. I\'m dissapointed.'
'>> Title: Good art, good price, poor design'
'>> Review: I had gotten the DC Vintage calendar the past two years, but it was on backorder forever this year and I saw they had shrunk the dimensions for no good reason. This one has good art choices but the design has the fold going through the picture, so it\'s less aesthetically pleasing, especially if you want to keep a picture to hang. For the price, a good calendar'
'>> Title: Helpful'
'>> Review: Nearly all the tips useful and. I consider myself an intermediate to advanced user of OneNote. I would highly recommend.'好的,我们可以看到这些评论并非严格关于书籍,可能涉及日历和 OneNote 等电子应用程序。尽管如此,这个领域似乎适合训练一个摘要模型。在我们查看适合这项任务的各种模型之前,我们还需要做最后一点数据准备:将英语和西班牙语的评论合并为一个单一的 DatasetDict 对象。🤗 Datasets 提供了一个方便的 concatenate_datasets() 函数,顾名思义,它将两个 Dataset 对象堆叠在一起。因此,为了创建我们的双语数据集,我们将遍历每个分割,拼接该分割的数据集,并对结果进行洗牌,以确保我们的模型不会过度适应单一语言:
from datasets import concatenate_datasets, DatasetDict
books_dataset = DatasetDict()
for split in english_books.keys():
books_dataset[split] = concatenate_datasets(
[english_books[split], spanish_books[split]]
)
books_dataset[split] = books_dataset[split].shuffle(seed=42)
# Peek at a few examples
show_samples(books_dataset)'>> Title: Easy to follow!!!!'
'>> Review: I loved The dash diet weight loss Solution. Never hungry. I would recommend this diet. Also the menus are well rounded. Try it. Has lots of the information need thanks.'
'>> Title: PARCIALMENTE DAÑADO'
'>> Review: Me llegó el día que tocaba, junto a otros libros que pedí, pero la caja llegó en mal estado lo cual dañó las esquinas de los libros porque venían sin protección (forro).'
'>> Title: no lo he podido descargar'
'>> Review: igual que el anterior'这看起来确实是英语和西班牙语评论的混合!现在我们有了训练语料库,最后要检查的是评论及其标题中词语的分布情况。这对于摘要任务尤为重要,因为数据中的短参考摘要可能会使模型在生成的摘要中只输出一两个词。下面的图表显示了词语分布情况,我们可以看到标题明显倾向于只使用1-2个词:
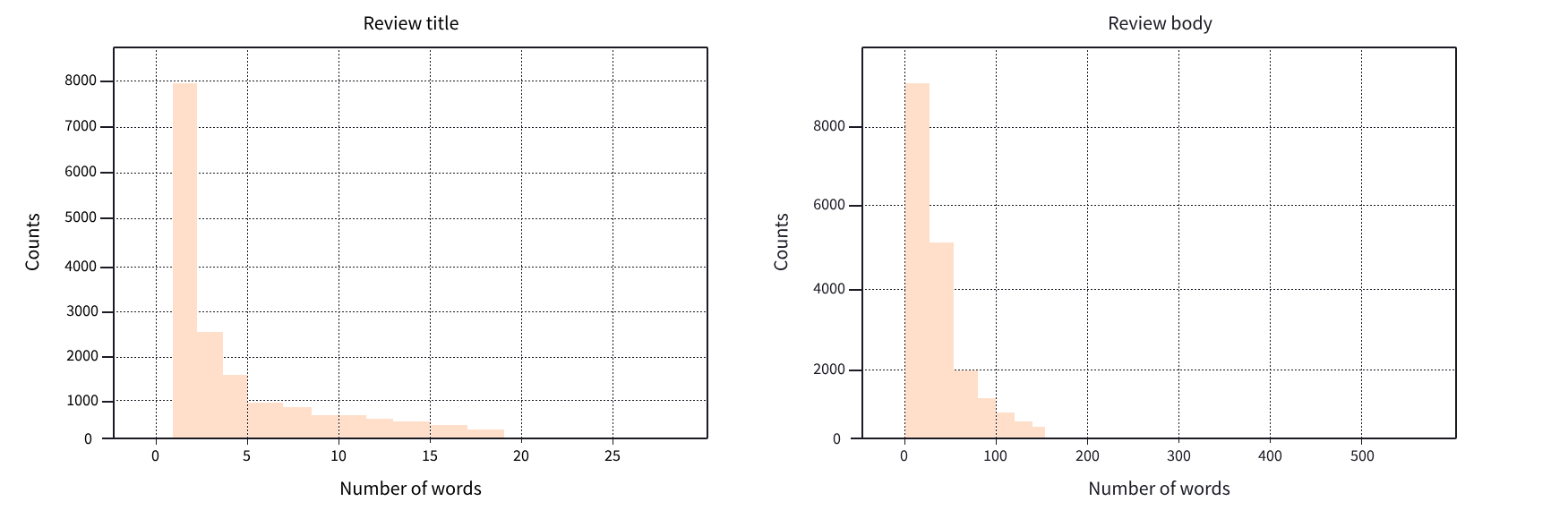
为了解决这个问题,我们将过滤掉那些标题非常短的示例,以便我们的模型能够生成更有趣的摘要。由于我们处理的是英语和西班牙语文本,我们可以使用一个粗略的启发式方法在空格处拆分标题,然后使用我们可靠的Dataset.filter()方法,如下所示:
books_dataset = books_dataset.filter(lambda x: len(x["review_title"].split()) > 2)现在我们已经准备好了我们的语料库,让我们来看看一些可能在上面进行微调的Transformer模型吧!
文本摘要的模型
如果你仔细想想,文本摘要的任务与机器翻译类似:我们有一段文本,比如一篇评论,我们希望将其“翻译”成一个更简短的版本,抓住输入的要点。因此,大多数用于摘要的Transformer模型采用了我们在第一章中首次遇到的编码器-解码器架构,尽管也有一些例外,比如GPT系列模型也可以用于少样本设置的摘要。下表列出了一些常用的预训练模型,可以进行摘要微调。
| Transformer model | Description | Multilingual? |
|---|---|---|
| GPT-2 | 尽管 GPT-2 是作为一个自回归语言模型训练的,但你可以通过在输入文本末尾添加“TL;DR”来让它生成摘要。 | ❌ |
| PEGASUS | 使用预训练目标来预测多句文本中的掩码句子。这个预训练目标比传统的语言建模更接近于摘要,在流行的基准测试中表现出色。 | ❌ |
| T5 | 一种通用的Transformer架构,在文本到文本的框架中表述所有任务;例如,模型对文档进行摘要的输入格式是summarize: ARTICLE。 | ❌ |
| mT5 | 基于多语言 Common Crawl 语料库(mC4)预训练的多语言版本 T5,涵盖 101 种语言。 | ✅ |
| BART | 一种新型Transformer架构,既有编码器又有解码器堆栈,经过训练后可以重建受损的输入,同时结合了BERT和GPT-2的预训练方案。 | ❌ |
| mBART-50 | BART的多语言版本,已在50种语言上进行了预训练。 | ✅ |
正如你从这张表中看到的,大多数用于摘要的Transformer模型(以及大多数NLP任务)都是单语的。如果你的任务涉及英语或德语等“资源丰富的”语言,这很不错,但对于世界上其他成千上万种语言来说则不然。幸运的是,有一类多语言Transformer模型,比如mT5和mBART,可以解决这个问题。这些模型使用语言建模进行预训练,但与传统方法不同的是,它们不是在一个语言的语料库上进行训练,而是同时在超过50种语言的文本上进行联合训练。
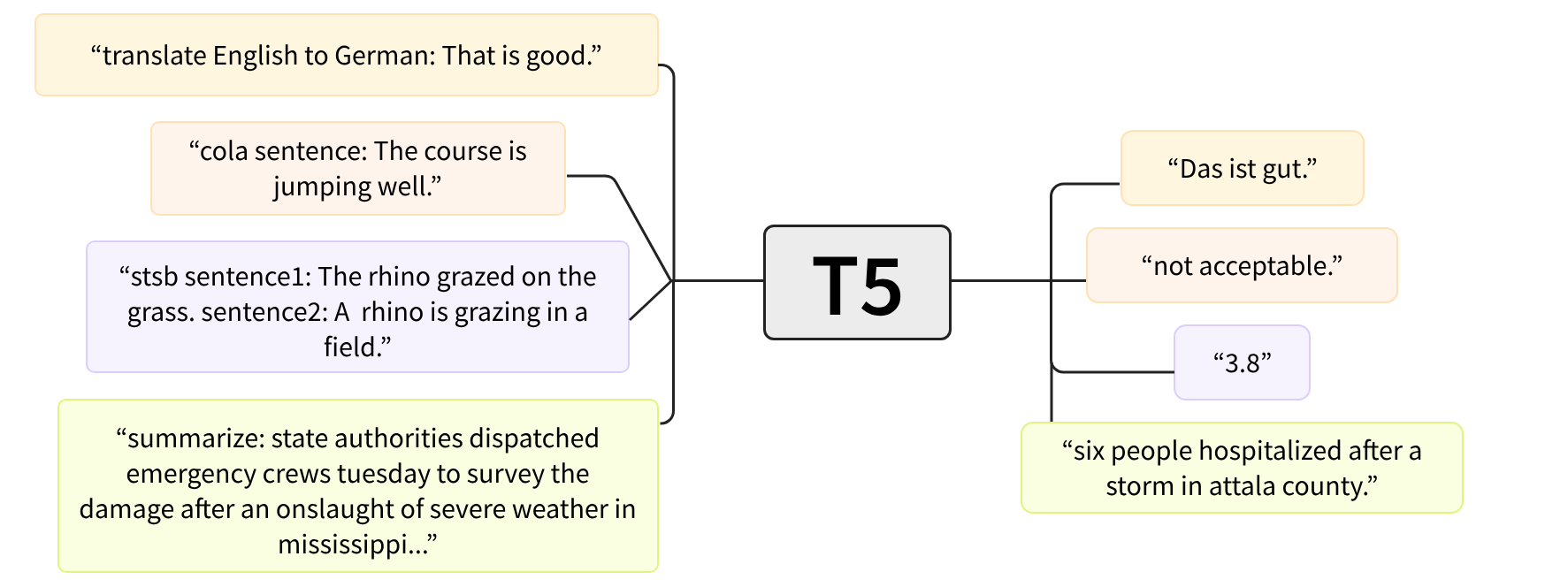
我们将重点关注mT5,这是一种基于T5的有趣架构,该架构在文本到文本框架中进行了预训练。在T5中,每个NLP任务都以提示前缀的形式表述,例如“summarize”,该提示条件模型将生成的文本与提示相匹配。如下图所示,这使得T5非常通用,因为您可以使用一个模型解决许多任务!
mT5不使用前缀,但拥有与T5类似的多样性,并具有多语言的优势。现在我们已经选定了模型,让我们看看如何准备数据进行训练。
✏️ 试试看!完成本节后,比较mT5和mBART的性能,使用相同的技术对后者进行微调。作为额外的挑战,您还可以尝试仅使用英文评论对T5进行微调。由于T5有一个特殊的前缀提示,您需要在下面的预处理步骤中在输入示例前添加“summarize:”。
预处理数据
我们接下来的任务是将我们的评论及其标题进行分词和编码。像往常一样,我们首先加载与预训练模型检查点相关的分词器。我们将使用mt5-small作为我们的检查点,以便我们能够在合理的时间内对模型进行微调:
from transformers import AutoTokenizer
model_checkpoint = "google/mt5-small"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)在NLP项目的早期阶段,一个好的做法是使用少量数据训练一系列“小型”模型。这可以让你更快地调试和迭代,朝着端到端的工作流程迈进。一旦你对结果感到满意,你可以随时通过更改模型检查点来扩大模型的规模!
让我们在一个小例子上测试一下 mT5 分词器:
inputs = tokenizer("I loved reading the Hunger Games!")
inputs{'input_ids': [336, 259, 28387, 11807, 287, 62893, 295, 12507, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}在这里,我们可以看到我们在第3章首次进行微调实验时遇到的熟悉的input_ids和attention_mask。让我们使用令牌化器的convert_ids_to_tokens()函数解码这些输入ID,看看我们正在使用的是哪种令牌化器:
tokenizer.convert_ids_to_tokens(inputs.input_ids)['▁I', '▁', 'loved', '▁reading', '▁the', '▁Hung', 'er', '▁Games', '</s>']特殊的 Unicode 字符 ▁ 和序列结束标记 表明我们正在使用 SentencePiece 分词器,它基于第 6 章讨论的 Unigram 分词算法。Unigram 对于多语言语料库尤其有用,因为它使 SentencePiece 能够忽略重音符号、标点符号,并且适用于许多像日语一样本身不包含空格字符的语言。
为了对我们的语料进行分词,我们需要处理与摘要任务相关的一个细节问题:由于我们的标签也是文本,因此它们有可能超出模型的最大上下文长度限制。这意味着我们需要对评论内容和标题同时进行截断处理,以确保输入不会过长。Hugging Face Transformers 中的分词器提供了一个便捷的 text_target 参数,允许你将标签与输入内容并行地进行分词处理。以下是如何为 mT5 模型处理输入和目标文本的一个示例:
max_input_length = 512
max_target_length = 30
def preprocess_function(examples):
model_inputs = tokenizer(
examples["review_body"],
max_length=max_input_length,
truncation=True,
)
labels = tokenizer(
examples["review_title"], max_length=max_target_length, truncation=True
)
model_inputs["labels"] = labels["input_ids"]
return model_inputs让我们逐步解析这段代码,理解其中发生了什么。首先,我们定义了 max_input_length 和 max_target_length 的值,它们分别设定了评论内容和标题的最大长度限制。由于评论正文通常比标题长得多,因此我们根据这个特点对这两个值进行了相应的设置。
接下来,在 preprocess_function() 中,我们就可以使用在整个课程中频繁使用的便捷方法 Dataset.map(),来轻松地对整个语料库进行分词处理:
tokenized_datasets = books_dataset.map(preprocess_function, batched=True)现在语料库已经完成了预处理,让我们来看一些常用于摘要任务的评估指标。我们会发现,在衡量机器生成文本的质量时,并不存在一种万能的评估方法。
💡 你可能已经注意到,我们在上面的
Dataset.map()函数中使用了batched=True。这会将样本以每批 1,000 条(默认值)的方式进行分批处理,并允许我们利用 Hugging Face Transformers 中快速分词器所支持的多线程功能。在可能的情况下,尽量使用batched=True,以提升预处理的效率!
文本摘要的度量标准
与本课程中介绍的大多数其他任务相比,评估摘要或翻译等文本生成任务的性能并没有那么直接。例如,对于一条评论:“I loved reading the Hunger Games”,可能存在多个合理的摘要,比如“I loved the Hunger Games”或者“Hunger Games is a great read”。显然,在生成的摘要和标签之间进行完全匹配(exact match)并不是一个好的解决方案——即使对人类来说,这种指标下的表现也可能很差,因为我们每个人的写作风格都不尽相同。
在摘要任务中,最常用的评估指标之一是 ROUGE 分数(Recall-Oriented Understudy for Gisting Evaluation,意为“面向召回率的摘要评测助手”)。该指标的基本思想是将生成的摘要与一组通常由人工撰写的参考摘要进行比较。
为了更具体地说明这一点,假设我们要比较以下两个摘要:
generated_summary = "I absolutely loved reading the Hunger Games"
reference_summary = "I loved reading the Hunger Games"一种比较方式是统计两个摘要中重叠的词语数量,在这个例子中有 6 个重叠词。然而,这种方法显得有些粗糙。因此,ROUGE 指标转而基于精确率(precision)和召回率(recall)来衡量重叠部分的匹配程度。
🙋 如果你第一次听说“精确率”和“召回率”也不用担心——接下来我们会通过一些具体的例子来清楚地解释它们。这两个指标通常出现在分类任务中,如果你想知道它们在分类场景下的定义,我们推荐查阅 scikit-learn 的官方指南。
在 ROUGE 中,召回率(recall)用于衡量生成的摘要覆盖参考摘要内容的程度。如果只是对词语进行比较,召回率可以通过以下公式计算:
$$ \mathrm{Recall} = \frac{\mathrm{Number,of,overlapping, words}}{\mathrm{Total, number, of, words, in, reference, summary}} $$
对于我们上面这个简单例子,这个公式给出的召回率是 6/6 = 1,也就是完美召回:模型生成的摘要包含了参考摘要中的所有词语。这听起来很好,但我们可以想象一个情况:如果生成的摘要其实是“I really really loved reading the Hunger Games all night”,这也仍然会得到完美的召回率,但从摘要的角度来看,这段文字显然更啰嗦、质量更差。
为了解决这类问题,我们还会计算精确率(precision)。在 ROUGE 的语境中,精确率衡量的是生成的摘要中有多少内容是相关的:
$$ \mathrm{Precision} = \frac{\mathrm{Number,of,overlapping, words}}{\mathrm{Total, number, of, words, in, generated, summary}} $$
将这个公式应用到我们那个啰嗦的摘要上,得到的精确率是 6/10 = 0.6,这明显比简洁版本的精确率 6/7 ≈ 0.86 要差不少。在实际应用中,通常会同时计算精确率和召回率,然后报告它们的调和平均数 —— F1 分数(F1-score)。
我们可以很容易地在 🤗 Datasets 中实现这一点,首先需要安装 rouge_score 包:
!pip install rouge_score然后按照以下方式加载 ROUGE 指标:
import evaluate
rouge_score = evaluate.load("rouge")然后我们可以使用 rouge_score.compute() 函数一次性计算所有指标:
scores = rouge_score.compute(
predictions=[generated_summary], references=[reference_summary]
)
scores{'rouge1': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
'rouge2': AggregateScore(low=Score(precision=0.67, recall=0.8, fmeasure=0.73), mid=Score(precision=0.67, recall=0.8, fmeasure=0.73), high=Score(precision=0.67, recall=0.8, fmeasure=0.73)),
'rougeL': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92)),
'rougeLsum': AggregateScore(low=Score(precision=0.86, recall=1.0, fmeasure=0.92), mid=Score(precision=0.86, recall=1.0, fmeasure=0.92), high=Score(precision=0.86, recall=1.0, fmeasure=0.92))}哇,这个输出中包含了很多信息——它们都代表什么意思呢?首先,🤗 Datasets 实际上会为精确率(precision)、召回率(recall)和 F1 分数(F1-score)计算置信区间,这些就是你在这里看到的 low(低)、mid(中)和 high(高)这三个属性。此外,🤗 Datasets 还计算了多种 ROUGE 分数(ROUGE scores),这些分数在比较生成摘要和参考摘要时基于不同粒度的文本单位。其中,rouge1 变体表示的是单字(unigram)的重叠情况——这其实只是对“单词重叠”的一种高级说法而已,也正是我们上面讨论过的评估指标。为了验证这一点,我们可以提取出分数中的 mid 值:
scores["rouge1"].midScore(precision=0.86, recall=1.0, fmeasure=0.92)太好了,精确率和召回率的数值对上了!那么那些其他的 ROUGE 分数又是什么意思呢?
- rouge2 衡量的是 bigram(双字)的重叠,也就是说,它关注的是连续两个词组成的词对之间的重叠情况。
- rougeL 和 rougeLsum 则衡量的是生成摘要和参考摘要之间 最长的连续匹配词序列,它们通过寻找两者中最长的公共子串来计算得分。
- 其中,rougeLsum 中的 “sum” 表示这个指标是针对整个摘要整体计算的,
- 而 rougeL 则是在每个单独的句子上计算,然后取平均值。
✏️ 动手试一试!自己创建一个生成摘要和参考摘要的例子,然后看看得出的 ROUGE 分数是否与根据精确率和召回率公式手动计算的结果一致。如果你想挑战一下,可以将文本拆分为二元组(bigrams),并对比 rouge2 指标的精确率和召回率。
我们将使用这些 ROUGE 分数来跟踪模型的性能,但在那之前,让我们先做一件每位优秀的 NLP 从业者都应该做的事:创建一个强大而简洁的基线模型(baseline)!
创建强大的基线
一个常见的文本摘要基线方法是简单地取文章的前三句话,这通常被称为“前导三句”(lead-3)基线。我们可以使用句号来识别句子边界,但这种方法在处理像 “U.S.” 或 “U.N.” 这样的缩写时会失败。因此,我们将改用 nltk 库,它包含了一个更优秀的算法来处理这些情况。你可以使用 pip 按如下方式安装这个库:
!pip install nltk然后下载标点符号规则:
import nltk
nltk.download("punkt")接下来,我们从nltk导入句子分词器,并创建一个简单的函数来提取评论中的前三句话。在文本摘要中,通常会用换行符来分隔每个摘要,所以我们也应该包括这一点,并在一个训练示例上进行测试:
from nltk.tokenize import sent_tokenize
def three_sentence_summary(text):
return "\n".join(sent_tokenize(text)[:3])
print(three_sentence_summary(books_dataset["train"][1]["review_body"]))'I grew up reading Koontz, and years ago, I stopped,convinced i had "outgrown" him.'
'Still,when a friend was looking for something suspenseful too read, I suggested Koontz.'
'She found Strangers.'这看起来是可行的,所以让我们现在实现一个函数,从数据集中提取这些”摘要”,并计算基准的ROUGE分数:
def evaluate_baseline(dataset, metric):
summaries = [three_sentence_summary(text) for text in dataset["review_body"]]
return metric.compute(predictions=summaries, references=dataset["review_title"])然后我们可以使用这个函数来计算验证集上的ROUGE分数,并使用Pandas对它们进行一些美化:
import pandas as pd
score = evaluate_baseline(books_dataset["validation"], rouge_score)
rouge_names = ["rouge1", "rouge2", "rougeL", "rougeLsum"]
rouge_dict = dict((rn, round(score[rn].mid.fmeasure * 100, 2)) for rn in rouge_names)
rouge_dict{'rouge1': 16.74, 'rouge2': 8.83, 'rougeL': 15.6, 'rougeLsum': 15.96}我们可以看到rouge2的得分明显低于其他得分;这可能是因为评论标题通常比较简短,因此lead-3的基线过于冗长。现在我们有了一个很好的基线作为基础,让我们把注意力转向微调mT5吧!
使用Trainer API微调mT5
为摘要任务微调模型与我们在本章中介绍的其他任务非常相似。我们需要做的第一件事是从 mt5-small 检查点加载预训练模型。由于摘要是一项序列到序列的任务,我们可以使用 AutoModelForSeq2SeqLM 类来加载模型,该类将自动下载并缓存权重:
from transformers import AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)💡如果你想知道为什么在下游任务中看不到任何关于微调模型的警告,那是因为对于序列到序列的任务,我们保留了网络的所有权重。相比之下,在第3章的文本分类模型中,预训练模型的头部被替换成了一个随机初始化的网络。
我们接下来需要做的是登录 Hugging Face Hub。如果你在笔记本中运行这段代码,你可以使用以下的实用函数来完成:
from huggingface_hub import notebook_login
notebook_login()这将显示一个小部件,您可以在其中输入您的凭证。或者,您可以在终端中运行此命令并在那里登录:
huggingface-cli login我们需要生成摘要以便在训练过程中计算ROUGE分数。幸运的是,🤗 Transformers提供了专门的Seq2SeqTrainingArguments和Seq2SeqTrainer类,可以自动为我们完成这项工作!为了了解这是如何工作的,让我们首先为我们的实验定义超参数和其他参数:
from transformers import Seq2SeqTrainingArguments
batch_size = 8
num_train_epochs = 8
# Show the training loss with every epoch
logging_steps = len(tokenized_datasets["train"]) // batch_size
model_name = model_checkpoint.split("/")[-1]
args = Seq2SeqTrainingArguments(
output_dir=f"{model_name}-finetuned-amazon-en-es",
evaluation_strategy="epoch",
learning_rate=5.6e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=num_train_epochs,
predict_with_generate=True,
logging_steps=logging_steps,
push_to_hub=True,
)在这里,我们设置了predict_with_generate参数,表示在评估过程中应该生成摘要,以便我们可以计算每个epoch的ROUGE分数。正如第1章所讨论的,解码器通过逐一预测令牌来进行推理,这通过模型的generate()方法实现。设置predict_with_generate=True告诉Seq2SeqTrainer在评估时使用该方法。
我们还调整了一些默认超参数,如学习率、训练轮数和权重衰减,并将 save_total_limit 选项设置为在训练过程中只保存最多 3 个检查点——这是因为即使是 mT5 的“小”版本也需要大约 1GB 的硬盘空间,通过限制保存的副本数量,我们可以节省一些空间。
push_to_hub=True 参数将允许我们在训练后将模型推送到 Hub;你可以在输出目录定义的位置的用户配置文件下找到存储库。请注意,你可以使用 hub_model_id 参数指定要推送到的存储库的名称(特别是,你必须使用这个参数来推送到一个组织)。例如,当我们将模型推送到 huggingface-course 组织时,我们在 Seq2SeqTrainingArguments 中添加了 hub_model_id=”huggingface-course/mt5-finetuned-amazon-en-es”。
接下来我们需要做的是为训练器提供一个 compute_metrics() 函数,以便我们可以在训练过程中对模型进行评估。对于摘要任务来说,这比简单地在模型预测结果上调用 rouge_score.compute() 要复杂一些,因为我们需要先将模型输出和标签解码为文本,然后才能计算 ROUGE 分数。以下函数正是实现了这一功能,并且还利用了来自 nltk 的 sent_tokenize() 函数,将摘要中的每个句子用换行符分隔开来:
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
# Decode generated summaries into text
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
# Decode reference summaries into text
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# ROUGE expects a newline after each sentence
decoded_preds = ["\n".join(sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(sent_tokenize(label.strip())) for label in decoded_labels]
# Compute ROUGE scores
result = rouge_score.compute(
predictions=decoded_preds, references=decoded_labels, use_stemmer=True
)
# Extract the median scores
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
return {k: round(v, 4) for k, v in result.items()}接下来,我们需要为我们的序列到序列任务定义一个数据整理器。由于mT5是一个编码器-解码器Transformer模型,在准备我们的批次时需要注意的一个细节是:在解码过程中,我们需要将标签向右移动一位。这是为了确保解码器只看到之前的真实标签,而不会看到当前或未来的标签,否则模型很容易记住这些信息。这类似于在因果语言建模等任务中对输入应用掩码自注意力机制的方式。
幸运的是,🤗 Transformers 提供了一个 DataCollatorForSeq2Seq 整理器,它将为我们动态填充输入和标记。要实例化这个整理器,我们只需要提供令牌化器和模型:
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)让我们看看当给这个数据整理器(collator)提供一个小批量示例时,它会产生什么样的输出。首先,我们需要移除包含字符串的列,因为整理器不知道如何对这些元素进行填充(padding):
tokenized_datasets = tokenized_datasets.remove_columns(
books_dataset["train"].column_names
)由于数据整理器(collator)期望接收一个字典列表,其中每个字典代表数据集中的一个单独样本,因此在将其传递给数据整理器之前,我们还需要将数据整理成预期的格式:
features = [tokenized_datasets["train"][i] for i in range(2)]
data_collator(features){'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]), 'input_ids': tensor([[ 1494, 259, 8622, 390, 259, 262, 2316, 3435, 955,
772, 281, 772, 1617, 263, 305, 14701, 260, 1385,
3031, 259, 24146, 332, 1037, 259, 43906, 305, 336,
260, 1, 0, 0, 0, 0, 0, 0],
[ 259, 27531, 13483, 259, 7505, 260, 112240, 15192, 305,
53198, 276, 259, 74060, 263, 260, 459, 25640, 776,
2119, 336, 259, 2220, 259, 18896, 288, 4906, 288,
1037, 3931, 260, 7083, 101476, 1143, 260, 1]]), 'labels': tensor([[ 7483, 259, 2364, 15695, 1, -100],
[ 259, 27531, 13483, 259, 7505, 1]]), 'decoder_input_ids': tensor([[ 0, 7483, 259, 2364, 15695, 1],
[ 0, 259, 27531, 13483, 259, 7505]])}这里需要注意的主要一点是,第一个样本的长度长于第二个样本,因此第二个样本的 input_ids 和 attention_mask 在右侧用 [PAD] 标记进行了填充(其 ID 为 0)。同样,我们可以看到 labels 被填充了 -100,这是为了确保损失函数忽略这些填充标记。最后,我们还可以看到一个新的 decoder_input_ids 字段,它通过在第一个位置插入 [PAD] 标记,将标签整体向右移动了一位。
我们终于有了训练所需的所有材料!现在只需要用标准参数实例化训练器即可:
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)并启动我们的训练运行:
trainer.train()在训练过程中,您应该看到训练损失减少,每个 epoch 的 ROUGE 分数增加。训练完成后,您可以通过运行 Trainer.evaluate() 来查看最终的 ROUGE 分数:
trainer.evaluate(){'eval_loss': 3.028524398803711,
'eval_rouge1': 16.9728,
'eval_rouge2': 8.2969,
'eval_rougeL': 16.8366,
'eval_rougeLsum': 16.851,
'eval_gen_len': 10.1597,
'eval_runtime': 6.1054,
'eval_samples_per_second': 38.982,
'eval_steps_per_second': 4.914}从分数我们可以看到,我们的模型轻松地超过了我们的 lead-3 基准——很不错!最后要做的是将模型权重推送到 Hub,具体步骤如下:
trainer.push_to_hub(commit_message="Training complete", tags="summarization")'https://huggingface.co/huggingface-course/mt5-finetuned-amazon-en-es/commit/aa0536b829b28e73e1e4b94b8a5aacec420d40e0'这会将检查点和配置文件保存到 output_dir,然后将所有文件上传到模型中心(Hub)。通过指定 tags 参数,我们还可以确保模型中心上的小部件(widget)适用于摘要流水线,而不是与 mT5 架构关联的默认文本生成流水线(有关模型标签的更多信息,请参见 🤗 Hub 文档)。trainer.push_to_hub() 的输出是一个指向 Git 提交哈希的 URL,因此你可以轻松查看对模型仓库所做的更改!
在结束这个部分之前,让我们来看看如何使用🤗 Accelerate提供的低级功能来微调mT5。
使用🤗 Accelerate对mT5进行微调
在🤗 Accelerate 中微调我们的模型与我们在第3章遇到的文本分类示例非常相似。主要的区别是需要在训练过程中显式地生成我们的摘要,并定义我们如何计算ROUGE分数(请记住,Seq2SeqTrainer已经为我们处理了生成部分)。让我们来看看如何在🤗 Accelerate 中实现这两个要求!
为训练做好一切准备
我们需要做的第一件事是为每个分割创建一个数据加载器。由于PyTorch数据加载器期望的是批次的张量,我们需要在我们的数据集中将格式设置为”torch”:
tokenized_datasets.set_format("torch")现在我们已经有了只包含张量的数据集,下一步就是再次实例化DataCollatorForSeq2Seq。为此,我们需要提供一个新的模型版本,所以让我们再次从缓存中加载它:
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)然后,我们可以实例化数据收集器并使用它来定义我们的数据加载器:
from torch.utils.data import DataLoader
batch_size = 8
train_dataloader = DataLoader(
tokenized_datasets["train"],
shuffle=True,
collate_fn=data_collator,
batch_size=batch_size,
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], collate_fn=data_collator, batch_size=batch_size
)接下来要做的是定义我们想要使用的优化器。和我们之前的例子一样,我们将使用AdamW,它对大多数问题都表现不错:
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=2e-5)最后,我们将我们的模型、优化器和数据加载器传递给加速器的 prepare() 方法:
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader
)🚨 如果你在使用 TPU 进行训练,你需要将上面的所有代码移动到一个专门的训练函数中。更多细节请查看第 3 章。
现在我们已经准备好了所需的对象,接下来还有三件事情需要完成:
- 定义学习率调度(schedule)。
- 实现一个函数,用于对摘要进行后处理,以便评估模型效果。
- 在 Hugging Face Hub 上创建一个仓库,以便我们可以将模型上传上去。
对于学习率调度,我们将采用之前章节中使用的标准线性调度方式:
from transformers import get_scheduler
num_train_epochs = 10
num_update_steps_per_epoch = len(train_dataloader)
num_training_steps = num_train_epochs * num_update_steps_per_epoch
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)对于后处理,我们需要一个函数,将生成的摘要分成由换行符分隔的句子。这是ROUGE指标所期望的格式,我们可以使用以下代码片段来实现:
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# ROUGE expects a newline after each sentence
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels如果你还记得我们是如何定义 Seq2SeqTrainer 的 compute_metrics() 函数的,那么这应该看起来很熟悉。
最后,我们需要在Hugging Face Hub上创建一个模型仓库。为此,我们可以使用名副其实的🤗 Hub库。我们只需要为我们的仓库定义一个名称,库中有一个实用函数可以将仓库ID与用户配置文件结合起来:
from huggingface_hub import get_full_repo_name
model_name = "test-bert-finetuned-squad-accelerate"
repo_name = get_full_repo_name(model_name)
repo_name'lewtun/mt5-finetuned-amazon-en-es-accelerate'现在我们可以使用这个仓库名称来克隆一个本地版本到我们的结果目录中,该目录将存储训练成果:
from huggingface_hub import Repository
output_dir = "results-mt5-finetuned-squad-accelerate"
repo = Repository(output_dir, clone_from=repo_name)这将使我们能够在训练过程中通过调用 repo.push_to_hub() 方法将工件推送回 Hub!现在让我们通过编写训练循环来结束我们的分析。
训练循环
用于摘要任务的训练循环与我们之前遇到的其他 🤗 Accelerate 示例非常相似,大致可以分为四个主要步骤:
- 训练模型:在每个训练周期(epoch)中遍历
train_dataloader中的所有样本,对模型进行训练。 - 生成摘要:在每个 epoch 结束时生成模型的摘要结果。首先生成预测的 token,然后将这些 token(以及参考摘要)解码为文本形式。
- 计算 ROUGE 分数:使用我们之前学到的技术来计算生成摘要与参考摘要之间的 ROUGE 指标,以评估模型性能。
- 保存检查点并上传到 Hub:保存模型的检查点,并将所有内容推送到 Hugging Face Hub。这里我们巧妙地使用了
Repository对象中的blocking=False参数,使得我们可以异步地按每个 epoch 上传检查点。这样即使上传一个大小为 GB 级别的模型时较慢,我们也可以继续进行下一轮的训练而不必等待上传完成!
以下代码块中展示了这些步骤的具体实现:
from tqdm.auto import tqdm
import torch
import numpy as np
progress_bar = tqdm(range(num_training_steps))
for epoch in range(num_train_epochs):
# Training
model.train()
for step, batch in enumerate(train_dataloader):
outputs = model(**batch)
loss = outputs.loss
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
# Evaluation
model.eval()
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
generated_tokens = accelerator.unwrap_model(model).generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
)
generated_tokens = accelerator.pad_across_processes(
generated_tokens, dim=1, pad_index=tokenizer.pad_token_id
)
labels = batch["labels"]
# If we did not pad to max length, we need to pad the labels too
labels = accelerator.pad_across_processes(
batch["labels"], dim=1, pad_index=tokenizer.pad_token_id
)
generated_tokens = accelerator.gather(generated_tokens).cpu().numpy()
labels = accelerator.gather(labels).cpu().numpy()
# Replace -100 in the labels as we can't decode them
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
if isinstance(generated_tokens, tuple):
generated_tokens = generated_tokens[0]
decoded_preds = tokenizer.batch_decode(
generated_tokens, skip_special_tokens=True
)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds, decoded_labels = postprocess_text(
decoded_preds, decoded_labels
)
rouge_score.add_batch(predictions=decoded_preds, references=decoded_labels)
# Compute metrics
result = rouge_score.compute()
# Extract the median ROUGE scores
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
result = {k: round(v, 4) for k, v in result.items()}
print(f"Epoch {epoch}:", result)
# Save and upload
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(output_dir, save_function=accelerator.save)
if accelerator.is_main_process:
tokenizer.save_pretrained(output_dir)
repo.push_to_hub(
commit_message=f"Training in progress epoch {epoch}", blocking=False
)Epoch 0: {'rouge1': 5.6351, 'rouge2': 1.1625, 'rougeL': 5.4866, 'rougeLsum': 5.5005}
Epoch 1: {'rouge1': 9.8646, 'rouge2': 3.4106, 'rougeL': 9.9439, 'rougeLsum': 9.9306}
Epoch 2: {'rouge1': 11.0872, 'rouge2': 3.3273, 'rougeL': 11.0508, 'rougeLsum': 10.9468}
Epoch 3: {'rouge1': 11.8587, 'rouge2': 4.8167, 'rougeL': 11.7986, 'rougeLsum': 11.7518}
Epoch 4: {'rouge1': 12.9842, 'rouge2': 5.5887, 'rougeL': 12.7546, 'rougeLsum': 12.7029}
Epoch 5: {'rouge1': 13.4628, 'rouge2': 6.4598, 'rougeL': 13.312, 'rougeLsum': 13.2913}
Epoch 6: {'rouge1': 12.9131, 'rouge2': 5.8914, 'rougeL': 12.6896, 'rougeLsum': 12.5701}
Epoch 7: {'rouge1': 13.3079, 'rouge2': 6.2994, 'rougeL': 13.1536, 'rougeLsum': 13.1194}
Epoch 8: {'rouge1': 13.96, 'rouge2': 6.5998, 'rougeL': 13.9123, 'rougeLsum': 13.7744}
Epoch 9: {'rouge1': 14.1192, 'rouge2': 7.0059, 'rougeL': 14.1172, 'rougeLsum': 13.9509}就这样了!一旦你运行这个,你就会得到一个模型和结果,跟我们用Trainer得到的结果非常相似。
使用您的微调模型
一旦你将模型推送到 Hub,你可以通过推理小部件或管道对象来使用它,具体步骤如下:
from transformers import pipeline
hub_model_id = "huggingface-course/mt5-small-finetuned-amazon-en-es"
summarizer = pipeline("summarization", model=hub_model_id)我们可以将测试集(模型尚未见过的数据)的一些示例输入到我们的管道中,以了解摘要的质量。首先,让我们实现一个简单的函数,显示评论、标题和生成的摘要:
def print_summary(idx):
review = books_dataset["test"][idx]["review_body"]
title = books_dataset["test"][idx]["review_title"]
summary = summarizer(books_dataset["test"][idx]["review_body"])[0]["summary_text"]
print(f"'>>> Review: {review}'")
print(f"\n'>>> Title: {title}'")
print(f"\n'>>> Summary: {summary}'")让我们来看看我们收到的其中一个英语例子:
print_summary(100)'>>> Review: Nothing special at all about this product... the book is too small and stiff and hard to write in. The huge sticker on the back doesn’t come off and looks super tacky. I would not purchase this again. I could have just bought a journal from the dollar store and it would be basically the same thing. It’s also really expensive for what it is.'
'>>> Title: Not impressed at all... buy something else'
'>>> Summary: Nothing special at all about this product'这还不错!我们可以看到,我们的模型通过用新词扩充评论的部分内容,实际上已经能够进行抽象式摘要了。也许我们模型最酷的方面是它是双语的,所以我们也可以生成西班牙语评论的摘要:
print_summary(0)'>>> Review: Es una trilogia que se hace muy facil de leer. Me ha gustado, no me esperaba el final para nada'
'>>> Title: Buena literatura para adolescentes'
'>>> Summary: Muy facil de leer'总结在英语中翻译为“非常容易阅读”,我们可以看到在这个例子中是直接从评论中提取出来的。尽管如此,这展示了mT5模型的多功能性,让你体验了一下处理多语言语料库的感觉!
接下来,我们将把注意力转向一个稍微复杂一些的任务:从零开始训练一个语言模型。
结语
第三百三十二篇博文写完,开心!!!!
今天,也是充满希望的一天。



