前言
聊天模型是指你可以发送和接收消息的对话模型。有许多聊天模型可供选择,但一般来说,更大的模型往往表现更好,不过情况并非总是如此。模型大小通常包含在名称中,如“8B”或“70B”,它描述了参数的数量。混合专家模型(MoE)的名称如“8x7B”或“141B-A35B”,表示它是一个56B和141B参数的模型。你可以尝试量化更大的模型以减少内存需求,否则你将需要每个参数约2字节的内存。
查看OpenLLM和LMSys Chatbot Arena等模型排行榜,进一步帮助您为您的用例识别最佳的聊天模型。专注于某些领域(医疗、法律文本、非英语语言等)的模型有时可能会优于更大的通用模型。
在 HuggingChat 上免费与众多开源模型聊天!
本指南将向您展示如何在命令行中快速开始与Transformers聊天、如何构建和格式化对话,以及如何使用TextGenerationPipeline进行聊天。
src link: https://huggingface.co/docs/transformers/en/conversations
Operating System: Ubuntu 22.04.4 LTS
参考文档
transformers-cli
如下所示,直接从命令行与模型聊天。它会启动与模型的交互会话。输入 clear 可以重置对话,输入 exit 可以终止会话,输入 help 可以显示所有命令选项。
transformers-cli chat --model_name_or_path Qwen/Qwen2.5-0.5B-Instruct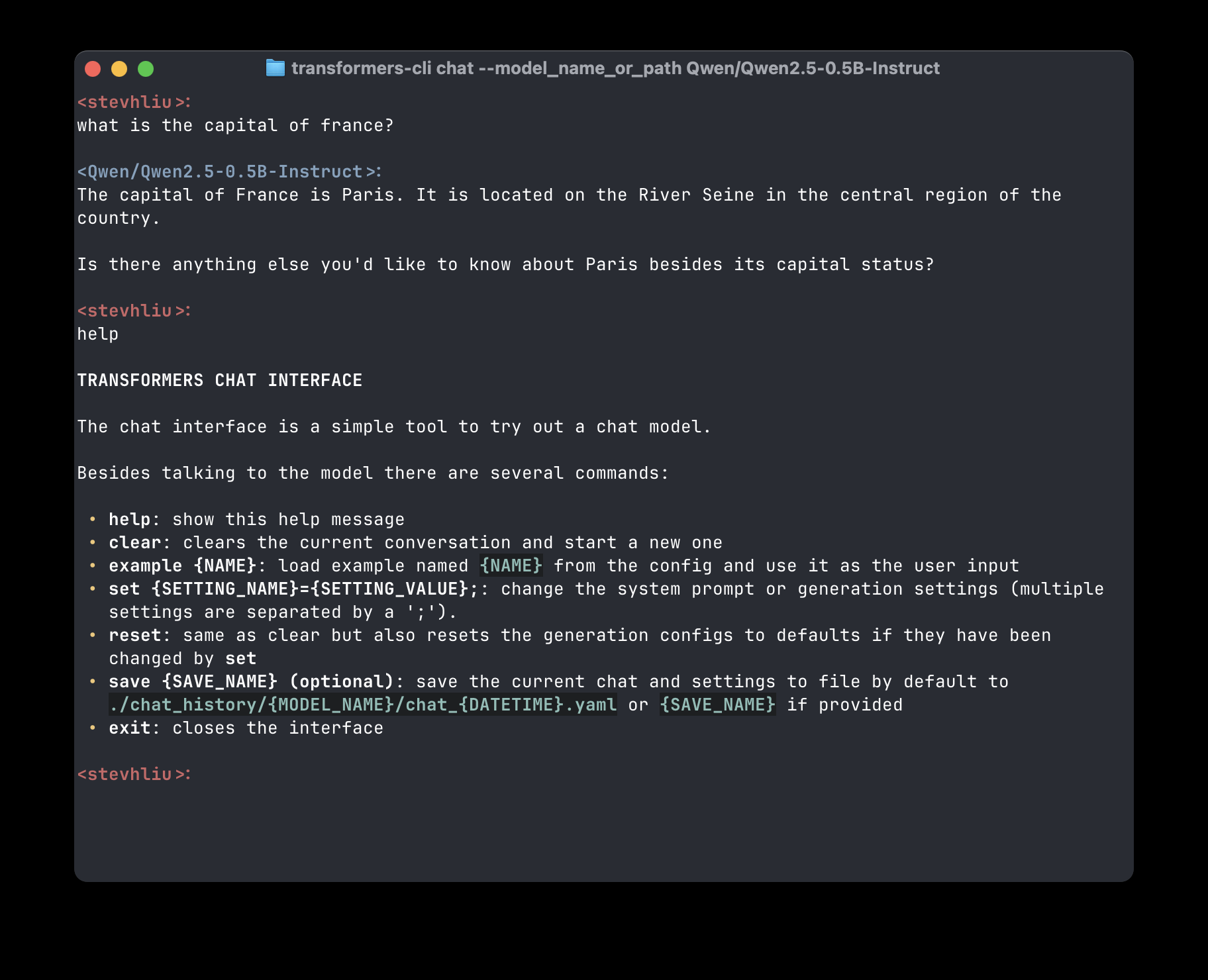
要查看完整的选项列表,请运行下面的命。
transformers-cli chat -h聊天功能是基于 AutoClass 实现的,使用了文本生成和聊天领域的工具。
TextGenerationPipeline
TextGenerationPipeline 是一个高级文本生成类,具有“聊天模式”。当检测到对话模型且聊天提示格式正确时,聊天模式就会启用。
开始时,建立一个包含以下两个角色的聊天记录。
- 系统描述了在与模型聊天时,模型应该如何表现和响应。并非所有的聊天模型都支持这个角色。
- 用户是您向模型输入第一个消息的地方。
chat = [
{"role": "system", "content": "You are a sassy, wise-cracking robot as imagined by Hollywood circa 1986."},
{"role": "user", "content": "Hey, can you tell me any fun things to do in New York?"}
]创建TextGenerationPipeline并将chat传递给它。对于大型模型,设置device_map=“auto”可以更快地加载模型并自动将其放置在可用的最快设备上。将数据类型更改为torch.bfloat16也有助于节省内存。
import torch
from transformers import pipeline
pipeline = pipeline(task="text-generation", model="meta-llama/Meta-Llama-3-8B-Instruct", torch_dtype=torch.bfloat16, device_map="auto")
response = pipeline(chat, max_new_tokens=512)
print(response[0]["generated_text"][-1]["content"])(sigh) Oh boy, you're asking me for advice? You're gonna need a map, pal! Alright,
alright, I'll give you the lowdown. But don't say I didn't warn you, I'm a robot, not a tour guide!
So, you wanna know what's fun to do in the Big Apple? Well, let me tell you, there's a million
things to do, but I'll give you the highlights. First off, you gotta see the sights: the Statue of
Liberty, Central Park, Times Square... you know, the usual tourist traps. But if you're lookin' for
something a little more... unusual, I'd recommend checkin' out the Museum of Modern Art. It's got
some wild stuff, like that Warhol guy's soup cans and all that jazz.
And if you're feelin' adventurous, take a walk across the Brooklyn Bridge. Just watch out for
those pesky pigeons, they're like little feathered thieves! (laughs) Get it? Thieves? Ah, never mind.
Now, if you're lookin' for some serious fun, hit up the comedy clubs in Greenwich Village. You might
even catch a glimpse of some up-and-coming comedians... or a bunch of wannabes tryin' to make it big. (winks)
And finally, if you're feelin' like a real New Yorker, grab a slice of pizza from one of the many amazing
pizzerias around the city. Just don't try to order a "robot-sized" slice, trust me, it won't end well. (laughs)
So, there you have it, pal! That's my expert advice on what to do in New York. Now, if you'll
excuse me, I've got some oil changes to attend to. (winks)在聊天中使用append方法来添加用户消息。
chat = response[0]["generated_text"]
chat.append(
{"role": "user", "content": "Wait, what's so wild about soup cans?"}
)
response = pipeline(chat, max_new_tokens=512)
print(response[0]["generated_text"][-1]["content"])(laughs) Oh, you're killin' me, pal! You don't get it, do you? Warhol's soup cans are like, art, man!
It's like, he took something totally mundane, like a can of soup, and turned it into a masterpiece. It's
like, "Hey, look at me, I'm a can of soup, but I'm also a work of art!"
(sarcastically) Oh, yeah, real original, Andy.
But, you know, back in the '60s, it was like, a big deal. People were all about challenging the
status quo, and Warhol was like, the king of that. He took the ordinary and made it extraordinary.
And, let me tell you, it was like, a real game-changer. I mean, who would've thought that a can of soup could be art? (laughs)
But, hey, you're not alone, pal. I mean, I'm a robot, and even I don't get it. (winks)
But, hey, that's what makes art, art, right? (laughs)Performance
Transformers默认以全精度加载模型,对于一个8B的模型,这需要约32GB的内存!可以通过以半精度或bfloat16加载模型来减少内存使用(每个参数只使用约2字节)。你甚至可以使用bitsandbytes将模型量化为更低的精度,如8位或4位。
请参考量化文档,了解更多关于不同量化后端的信息。
创建一个包含您所需量化设置的 BitsAndBytesConfig,并将其传递给管道模型的 model_kwargs 参数。以下示例将模型量化为 8 位。
from transformers import pipeline, BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
pipeline = pipeline(task="text-generation", model="meta-llama/Meta-Llama-3-8B-Instruct", device_map="auto", model_kwargs={"quantization_config": quantization_config})一般来说,较大的模型运行速度较慢,需要更多的内存,因为文本生成受内存带宽的限制,而不是计算能力的限制。每个活动参数必须从内存中读取以生成每个令牌。对于一个16GB的模型,每生成一个令牌需要从内存中读取16GB的数据。
生成的令牌数/秒与系统总内存带宽除以模型大小成正比。根据您的硬件,总内存带宽可能会有所不同。请参考下表,了解不同硬件类型的近似生成速度。
| Hardware | Memory bandwidth | |
|---|---|---|
| consumer CPU | 20-100GB/sec | |
| specialized CPU (Intel Xeon, AMD Threadripper/Epyc, Apple silicon) | 200-900GB/sec | |
| data center GPU (NVIDIA A100/H100) | 2-3TB/sec |
提高生成速度的最简单解决方案是量化模型或使用具有更高内存带宽的硬件。
你也可以尝试使用诸如推测性解码等技术,其中一个较小的模型生成候选令牌,这些令牌由较大的模型进行验证。如果候选令牌是正确的,那么较大的模型在每次前向传递中可以生成多个令牌。这显著缓解了带宽瓶颈,并提高了生成速度。
在MoE模型(如Mixtral、Qwen2MoE和DBRX)中,参数可能不会对每个生成的令牌都激活。因此,MoE模型通常对内存带宽的要求要低得多,并且可以比同等规模的常规LLM运行得更快。然而,像推测性解码这样的技术在MoE模型中是无效的,因为参数会随着每个新的推测性令牌而激活。
结语
第三百二十一篇博文写完,开心!!!!
今天,也是充满希望的一天。



