前言
tiktoken 是一个快速的 BPE 分词器,用于 OpenAI 的模型。
import tiktoken
enc = tiktoken.get_encoding("o200k_base")
assert enc.decode(enc.encode("hello world")) == "hello world"
# To get the tokeniser corresponding to a specific model in the OpenAI API:
enc = tiktoken.encoding_for_model("gpt-4o")tiktoken的开源版本可以从PyPI安装:
pip install tiktoken分词器 API 在 tiktoken/core.py 中有文档记录。
使用 tiktoken 的示例代码可以在 OpenAI Cookbook 中找到。
Operating System: Ubuntu 22.04.4 LTS
参考文档
性能
tiktoken 的速度比一个类似的开源分词器快 3-6 倍。
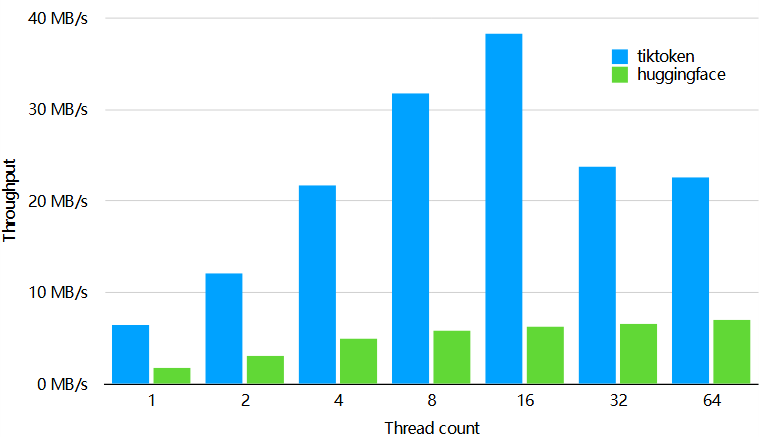
在 1GB 的文本上使用 GPT-2 分词器进行性能测试,使用了 tokenizers==0.13.2、transformers==4.24.0 和 tiktoken==0.2.0 版本。
BPE到底是什么?
语言模型不像你和我一样看文本,而是看一系列数字(称为 tokens)。字节对编码(BPE)是将文本转换为 tokens 的一种方法。它有几个理想的特性:
- 它是可逆且无损的,所以你可以将 tokens 转换回原始文本。
- 它适用于任意文本,即使是分词器训练数据中不包含的文本。
- 它压缩文本:token 序列比原始文本对应的字节短。实际上,平均每个 token 大约对应 4 个字节。
- 它试图让模型看到常见的子词。例如,”ing” 是英语中的一个常见子词,所以 BPE 编码通常会将有 “encoding” 分割成如 “encod” 和 “ing” 这样的 tokens(而不是例如 “enc” 和 “oding”)。因为模型会一次又一次地在不同上下文中看到 “ing” 这个 token,所以它帮助模型泛化和更好地理解语法。
tiktoken 包含一个教育性子模块,如果你想了解更多关于 BPE 的细节,它更友好,包括帮助可视化 BPE 过程的代码。
from tiktoken._educational import *
# Train a BPE tokeniser on a small amount of text
enc = train_simple_encoding()
# Visualise how the GPT-4 encoder encodes text
enc = SimpleBytePairEncoding.from_tiktoken("cl100k_base")
enc.encode("hello world aaaaaaaaaaaa")扩展 tiktoken
你可能希望扩展 Tiktoken 以支持新的编码。有两种方法可以做到这一点。
- 按照你想要的方式精确创建你的 Encoding 对象,并简单地传递它。
cl100k_base = tiktoken.get_encoding("cl100k_base")
# In production, load the arguments directly instead of accessing private attributes
# See openai_public.py for examples of arguments for specific encodings
enc = tiktoken.Encoding(
# If you're changing the set of special tokens, make sure to use a different name
# It should be clear from the name what behaviour to expect.
name="cl100k_im",
pat_str=cl100k_base._pat_str,
mergeable_ranks=cl100k_base._mergeable_ranks,
special_tokens={
**cl100k_base._special_tokens,
"<|im_start|>": 100264,
"<|im_end|>": 100265,
}
)- 使用 tiktoken_ext 插件机制将你的 Encoding 对象注册到 tiktoken。
如果你需要 tiktoken.get_encoding 找到你的编码,这才有用,否则请优先选择选项 1。
为此,你需要在 tiktoken_ext 下创建一个命名空间包。
像这样布局你的项目,并确保省略 tiktoken_ext/__init__.py 文件:
my_tiktoken_extension
├── tiktoken_ext
│ └── my_encodings.py
└── setup.pymy_encodings.py 应该是一个包含名为 ENCODING_CONSTRUCTORS 的变量的模块。这是一个从编码名称到函数的字典,该函数不接受任何参数,并返回可以传递给 tiktoken.Encoding 以构建该编码的参数。例如,请参见 tiktoken_ext/openai_public.py。有关精确细节,请参见 tiktoken/registry.py。
你的 setup.py 应该看起来像这样:
from setuptools import setup, find_namespace_packages
setup(
name="my_tiktoken_extension",
packages=find_namespace_packages(include=['tiktoken_ext*']),
install_requires=["tiktoken"],
...
)然后简单地使用 pip install ./my_tiktoken_extension,你应该能够使用你的自定义编码了!确保不要使用可编辑安装。
如何使用 tiktoken 计算 tokens
tiktoken 是 OpenAI 提供的一个快速开源分词器。
给定一个文本字符串(例如,”tiktoken is great!”)和一个编码(例如,”cl100k_base”),分词器可以将文本字符串分割成一个 tokens 列表(例如,[“t”, “ik”, “token”, “ is”, “ great”, “!”])。
将文本字符串分割成 tokens 很有用,因为 GPT 模型以 tokens 的形式查看文本。知道一个文本字符串中有多少 tokens 可以告诉你(a)这个字符串是否太长,以至于文本模型无法处理,以及(b)一个 OpenAI API 调用的成本是多少(因为使用量是按 token 计价的)。
Encodings
编码指定文本如何转换为 tokens。不同的模型使用不同的编码。
tiktoken 支持由 OpenAI 模型使用的三种编码:
| Encoding name | OpenAI models |
|---|---|
o200k_base |
gpt-4o, gpt-4o-mini |
cl100k_base |
gpt-4-turbo, gpt-4, gpt-3.5-turbo, text-embedding-ada-002, text-embedding-3-small, text-embedding-3-large |
p50k_base |
Codex models, text-davinci-002, text-davinci-003 |
r50k_base (or gpt2) |
GPT-3 models like davinci |
你可以使用 tiktoken.encoding_for_model() 来获取模型的编码,如下所示:
encoding = tiktoken.encoding_for_model('gpt-4o-mini')注意,p50k_base 与 r50k_base 有很大重叠,对于非代码应用,它们通常会给出相同的 tokens。
按语言划分的分词器库
对于 o200k_base、cl100k_base 和 p50k_base 编码:
- Python: tiktoken
- .NET / C#: SharpToken, TiktokenSharp
- Java: jtokkit
- Golang: tiktoken-go
- Rust: tiktoken-rs
对于 r50k_base (gpt2) 编码,分词器支持多种语言。
- Python: tiktoken (or alternatively GPT2TokenizerFast)
- JavaScript: gpt-3-encoder
- .NET / C#: GPT Tokenizer
- Java: gpt2-tokenizer-java
- PHP: GPT-3-Encoder-PHP
- Golang: tiktoken-go
- Rust: tiktoken-rs
(OpenAI 不对第三方库进行任何背书或保证。)
字符串通常是如何被分词的
在英语中,tokens 的长度通常从一个字符到一个单词不等(例如,”t” 或 “ great”),尽管在某些语言中,tokens 可以短于一个字符或长于一个单词。空格通常与单词的开头组合在一起(例如,” is” 而不是 “is “ 或 “ “+ “is”)。你可以快速在 OpenAI Tokenizer 或第三方 Tiktokenizer 网络应用程序中检查一个字符串是如何被分词的。
安装 tiktoken
如果需要,使用 pip 安装 tiktoken:
%pip install --upgrade tiktoken -q
%pip install --upgrade openai -q[notice] A new release of pip is available: 24.0 -> 24.2
[notice] To update, run: pip install --upgrade pip
Note: you may need to restart the kernel to use updated packages.
[notice] A new release of pip is available: 24.0 -> 24.2
[notice] To update, run: pip install --upgrade pip
Note: you may need to restart the kernel to use updated packages.导入 tiktoken
import tiktoken加载一个编码
使用 tiktoken.get_encoding() 通过名称加载一个编码。
第一次运行时,它将需要一个互联网连接来下载。后来的运行不需要互联网连接。
encoding = tiktoken.get_encoding("cl100k_base")使用 tiktoken.encoding_for_model() 自动加载给定模型名称的正确编码。
encoding = tiktoken.encoding_for_model("gpt-4o-mini")使用 encoding.encode() 将文本转换为 tokens
.encode() 方法将文本字符串转换为 token 整数列表。
encoding.encode("tiktoken is great!")[83, 8251, 2488, 382, 2212, 0]通过计算 .encode() 返回的列表的长度来计算 tokens 的数量。
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokensnum_tokens_from_string("tiktoken is great!", "o200k_base")6使用 encoding.decode() 将 tokens 转换为文本
.decode() 方法将 token 整数列表转换回字符串。
encoding.decode([83, 8251, 2488, 382, 2212, 0])'tiktoken is great!'警告:尽管 .decode() 可以应用于单个 tokens,但请注意,对于不在 utf-8 边界上的 tokens,它可能会丢失信息。
对于单个 tokens,.decode_single_token_bytes() 安全地将单个整数 token 转换为它所代表的字节。
[encoding.decode_single_token_bytes(token) for token in [83, 8251, 2488, 382, 2212, 0]][b't', b'ikt', b'oken', b' is', b' great', b'!'](字符串前的 b 表示这些字符串是字节字符串。)
比较编码
不同的编码在分割单词、组合空格和处理非英语字符方面有所不同。使用上述方法,我们可以比较几个示例字符串上的不同编码。
def compare_encodings(example_string: str) -> None:
"""Prints a comparison of three string encodings."""
# print the example string
print(f'\nExample string: "{example_string}"')
# for each encoding, print the # of tokens, the token integers, and the token bytes
for encoding_name in ["r50k_base", "p50k_base", "cl100k_base", "o200k_base"]:
encoding = tiktoken.get_encoding(encoding_name)
token_integers = encoding.encode(example_string)
num_tokens = len(token_integers)
token_bytes = [encoding.decode_single_token_bytes(token) for token in token_integers]
print()
print(f"{encoding_name}: {num_tokens} tokens")
print(f"token integers: {token_integers}")
print(f"token bytes: {token_bytes}")compare_encodings("antidisestablishmentarianism")Example string: "antidisestablishmentarianism"
r50k_base: 5 tokens
token integers: [415, 29207, 44390, 3699, 1042]
token bytes: [b'ant', b'idis', b'establishment', b'arian', b'ism']
p50k_base: 5 tokens
token integers: [415, 29207, 44390, 3699, 1042]
token bytes: [b'ant', b'idis', b'establishment', b'arian', b'ism']
cl100k_base: 6 tokens
token integers: [519, 85342, 34500, 479, 8997, 2191]
token bytes: [b'ant', b'idis', b'establish', b'ment', b'arian', b'ism']
o200k_base: 6 tokens
token integers: [493, 129901, 376, 160388, 21203, 2367]
token bytes: [b'ant', b'idis', b'est', b'ablishment', b'arian', b'ism']compare_encodings("2 + 2 = 4")Example string: "2 + 2 = 4"
r50k_base: 5 tokens
token integers: [17, 1343, 362, 796, 604]
token bytes: [b'2', b' +', b' 2', b' =', b' 4']
p50k_base: 5 tokens
token integers: [17, 1343, 362, 796, 604]
token bytes: [b'2', b' +', b' 2', b' =', b' 4']
cl100k_base: 7 tokens
token integers: [17, 489, 220, 17, 284, 220, 19]
token bytes: [b'2', b' +', b' ', b'2', b' =', b' ', b'4']
o200k_base: 7 tokens
token integers: [17, 659, 220, 17, 314, 220, 19]
token bytes: [b'2', b' +', b' ', b'2', b' =', b' ', b'4']compare_encodings("お誕生日おめでとう")Example string: "お誕生日おめでとう"
r50k_base: 14 tokens
token integers: [2515, 232, 45739, 243, 37955, 33768, 98, 2515, 232, 1792, 223, 30640, 30201, 29557]
token bytes: [b'\xe3\x81', b'\x8a', b'\xe8\xaa', b'\x95', b'\xe7\x94\x9f', b'\xe6\x97', b'\xa5', b'\xe3\x81', b'\x8a', b'\xe3\x82', b'\x81', b'\xe3\x81\xa7', b'\xe3\x81\xa8', b'\xe3\x81\x86']
p50k_base: 14 tokens
token integers: [2515, 232, 45739, 243, 37955, 33768, 98, 2515, 232, 1792, 223, 30640, 30201, 29557]
token bytes: [b'\xe3\x81', b'\x8a', b'\xe8\xaa', b'\x95', b'\xe7\x94\x9f', b'\xe6\x97', b'\xa5', b'\xe3\x81', b'\x8a', b'\xe3\x82', b'\x81', b'\xe3\x81\xa7', b'\xe3\x81\xa8', b'\xe3\x81\x86']
cl100k_base: 9 tokens
token integers: [33334, 45918, 243, 21990, 9080, 33334, 62004, 16556, 78699]
token bytes: [b'\xe3\x81\x8a', b'\xe8\xaa', b'\x95', b'\xe7\x94\x9f', b'\xe6\x97\xa5', b'\xe3\x81\x8a', b'\xe3\x82\x81', b'\xe3\x81\xa7', b'\xe3\x81\xa8\xe3\x81\x86']
o200k_base: 8 tokens
token integers: [8930, 9697, 243, 128225, 8930, 17693, 4344, 48669]
token bytes: [b'\xe3\x81\x8a', b'\xe8\xaa', b'\x95', b'\xe7\x94\x9f\xe6\x97\xa5', b'\xe3\x81\x8a', b'\xe3\x82\x81', b'\xe3\x81\xa7', b'\xe3\x81\xa8\xe3\x81\x86']计算聊天补全 API 调用的 tokens 数量
像 gpt-4o-mini 和 gpt-4 这样的 ChatGPT 模型使用 tokens 的方式与旧的补全模型相同,但由于它们基于消息的格式,计算一次对话将使用多少 tokens 更为困难。
下面是一个示例函数,用于计算传递给 gpt-3.5-turbo、gpt-4、gpt-4o 和 gpt-4o-mini 的消息的 tokens 数量。
请注意,从消息中计算 tokens 的确切方式可能会从模型到模型有所不同。考虑以下函数计算的数字是一个估计值,而不是一个永恒的保证。
特别是,使用可选函数输入的请求将在下面计算的估计值之上消耗额外的 tokens。
def num_tokens_from_messages(messages, model="gpt-4o-mini-2024-07-18"):
"""Return the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using o200k_base encoding.")
encoding = tiktoken.get_encoding("o200k_base")
if model in {
"gpt-3.5-turbo-0125",
"gpt-4-0314",
"gpt-4-32k-0314",
"gpt-4-0613",
"gpt-4-32k-0613",
"gpt-4o-mini-2024-07-18",
"gpt-4o-2024-08-06"
}:
tokens_per_message = 3
tokens_per_name = 1
elif "gpt-3.5-turbo" in model:
print("Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0125.")
return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0125")
elif "gpt-4o-mini" in model:
print("Warning: gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-mini-2024-07-18.")
return num_tokens_from_messages(messages, model="gpt-4o-mini-2024-07-18")
elif "gpt-4o" in model:
print("Warning: gpt-4o and gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-2024-08-06.")
return num_tokens_from_messages(messages, model="gpt-4o-2024-08-06")
elif "gpt-4" in model:
print("Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.")
return num_tokens_from_messages(messages, model="gpt-4-0613")
else:
raise NotImplementedError(
f"""num_tokens_from_messages() is not implemented for model {model}."""
)
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens# let's verify the function above matches the OpenAI API response
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY", "<your OpenAI API key if not set as env var>"))
example_messages = [
{
"role": "system",
"content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.",
},
{
"role": "system",
"name": "example_user",
"content": "New synergies will help drive top-line growth.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Things working well together will increase revenue.",
},
{
"role": "system",
"name": "example_user",
"content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Let's talk later when we're less busy about how to do better.",
},
{
"role": "user",
"content": "This late pivot means we don't have time to boil the ocean for the client deliverable.",
},
]
for model in [
"gpt-3.5-turbo",
"gpt-4-0613",
"gpt-4",
"gpt-4o",
"gpt-4o-mini"
]:
print(model)
# example token count from the function defined above
print(f"{num_tokens_from_messages(example_messages, model)} prompt tokens counted by num_tokens_from_messages().")
# example token count from the OpenAI API
response = client.chat.completions.create(model=model,
messages=example_messages,
temperature=0,
max_tokens=1)
print(f'{response.usage.prompt_tokens} prompt tokens counted by the OpenAI API.')
print()gpt-3.5-turbo
Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0125.
129 prompt tokens counted by num_tokens_from_messages().
129 prompt tokens counted by the OpenAI API.
gpt-4-0613
129 prompt tokens counted by num_tokens_from_messages().
129 prompt tokens counted by the OpenAI API.
gpt-4
Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.
129 prompt tokens counted by num_tokens_from_messages().
129 prompt tokens counted by the OpenAI API.
gpt-4o
Warning: gpt-4o and gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-2024-08-06.
124 prompt tokens counted by num_tokens_from_messages().
124 prompt tokens counted by the OpenAI API.
gpt-4o-mini
Warning: gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-mini-2024-07-18.
124 prompt tokens counted by num_tokens_from_messages().
124 prompt tokens counted by the OpenAI API.计算带有工具调用的聊天补全的 tokens 数量
接下来,我们将研究如何将这些计算应用于可能包含函数调用的消息。由于工具本身的格式,这并不是立即显而易见的。
下面是一个示例函数,用于计算传递给 gpt-3.5-turbo、gpt-4、gpt-4o 和 gpt-4o-mini 的包含工具的消息的 tokens 数量。
def num_tokens_for_tools(functions, messages, model):
# Initialize function settings to 0
func_init = 0
prop_init = 0
prop_key = 0
enum_init = 0
enum_item = 0
func_end = 0
if model in [
"gpt-4o",
"gpt-4o-mini"
]:
# Set function settings for the above models
func_init = 7
prop_init = 3
prop_key = 3
enum_init = -3
enum_item = 3
func_end = 12
elif model in [
"gpt-3.5-turbo",
"gpt-4"
]:
# Set function settings for the above models
func_init = 10
prop_init = 3
prop_key = 3
enum_init = -3
enum_item = 3
func_end = 12
else:
raise NotImplementedError(
f"""num_tokens_for_tools() is not implemented for model {model}."""
)
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using o200k_base encoding.")
encoding = tiktoken.get_encoding("o200k_base")
func_token_count = 0
if len(functions) > 0:
for f in functions:
func_token_count += func_init # Add tokens for start of each function
function = f["function"]
f_name = function["name"]
f_desc = function["description"]
if f_desc.endswith("."):
f_desc = f_desc[:-1]
line = f_name + ":" + f_desc
func_token_count += len(encoding.encode(line)) # Add tokens for set name and description
if len(function["parameters"]["properties"]) > 0:
func_token_count += prop_init # Add tokens for start of each property
for key in list(function["parameters"]["properties"].keys()):
func_token_count += prop_key # Add tokens for each set property
p_name = key
p_type = function["parameters"]["properties"][key]["type"]
p_desc = function["parameters"]["properties"][key]["description"]
if "enum" in function["parameters"]["properties"][key].keys():
func_token_count += enum_init # Add tokens if property has enum list
for item in function["parameters"]["properties"][key]["enum"]:
func_token_count += enum_item
func_token_count += len(encoding.encode(item))
if p_desc.endswith("."):
p_desc = p_desc[:-1]
line = f"{p_name}:{p_type}:{p_desc}"
func_token_count += len(encoding.encode(line))
func_token_count += func_end
messages_token_count = num_tokens_from_messages(messages, model)
total_tokens = messages_token_count + func_token_count
return total_tokenstools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string",
"description": "The unit of temperature to return",
"enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
}
]
example_messages = [
{
"role": "system",
"content": "You are a helpful assistant that can answer to questions about the weather.",
},
{
"role": "user",
"content": "What's the weather like in San Francisco?",
},
]
for model in [
"gpt-3.5-turbo",
"gpt-4",
"gpt-4o",
"gpt-4o-mini"
]:
print(model)
# example token count from the function defined above
print(f"{num_tokens_for_tools(tools, example_messages, model)} prompt tokens counted by num_tokens_for_tools().")
# example token count from the OpenAI API
response = client.chat.completions.create(model=model,
messages=example_messages,
tools=tools,
temperature=0)
print(f'{response.usage.prompt_tokens} prompt tokens counted by the OpenAI API.')
print()gpt-3.5-turbo
Warning: gpt-3.5-turbo may update over time. Returning num tokens assuming gpt-3.5-turbo-0125.
105 prompt tokens counted by num_tokens_for_tools().
105 prompt tokens counted by the OpenAI API.
gpt-4
Warning: gpt-4 may update over time. Returning num tokens assuming gpt-4-0613.
105 prompt tokens counted by num_tokens_for_tools().
105 prompt tokens counted by the OpenAI API.
gpt-4o
Warning: gpt-4o and gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-2024-08-06.
101 prompt tokens counted by num_tokens_for_tools().
101 prompt tokens counted by the OpenAI API.
gpt-4o-mini
Warning: gpt-4o-mini may update over time. Returning num tokens assuming gpt-4o-mini-2024-07-18.
101 prompt tokens counted by num_tokens_for_tools().
101 prompt tokens counted by the OpenAI API.结语
第三百零四篇博文写完,开心!!!!
今天,也是充满希望的一天。



