前言
Hugging Face 的官网地址为:https://huggingface.co/ 。
镜像网站: https://hf-mirror.com/
操作系统:Windows 10 专业版
参考文档
模型缓存位置
transformers
source link: https://huggingface.co/docs/transformers/installation#cache-setup
- 编辑
~/.bashrc:
vim ~/.bashrc- 在文件中添加如下内容:
export HUGGINGFACE_HUB_CACHE=/data/.cache/huggingface/hub- 保存退出后,运行以下命令使设置生效:
source ~/.bashrcmodelscope
source link: https://modelscope.cn/docs/%E6%A8%A1%E5%9E%8B%E7%9A%84%E4%B8%8B%E8%BD%BD
- 编辑
~/.bashrc:
vim ~/.bashrc- 在文件中添加如下内容:
export MODELSCOPE_CACHE=/data/.cache/modelscope- 保存退出后,运行以下命令使设置生效:
source ~/.bashrc镜像网站
源教程地址: https://blog.csdn.net/mar1111s/article/details/137179180 .
设置环境变量方法如下:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"Linux 运行下面的命令或者将其写入 ~/.bashrc。
- 编辑
~/.bashrc:
vim ~/.bashrc- 在文件中添加如下内容:
export HF_ENDPOINT=https://hf-mirror.com- 保存退出后,运行以下命令使设置生效:
source ~/.bashrc下载模型
"""
link1: https://huggingface.co/meta-llama/Llama-3.2-1B
link2: https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
link3: https://modelscope.cn/models/LLM-Research/Llama-3.2-1B-Instruct
"""
import torch
from transformers import pipeline
from modelscope import snapshot_download
model_dir = snapshot_download('LLM-Research/Llama-3.2-1B-Instruct')
pipe = pipeline(
"text-generation",
model=model_dir,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
terminators = [
pipe.tokenizer.eos_token_id,
pipe.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipe(
messages,
max_new_tokens=256,
eos_token_id=terminators,
)
print(outputs[0]["generated_text"][-1]["content"])
print(f"{'*'*42}")
print(pipe("The key to life is", max_new_tokens=100, eos_token_id=terminators))保存模型
源教程地址: https://huggingface.co/docs/transformers/quicktour#save-a-model .
Once your model is fine-tuned, you can save it with its tokenizer using PreTrainedModel.save_pretrained():
pt_save_directory = "./pt_save_pretrained"
tokenizer.save_pretrained(pt_save_directory)
pt_model.save_pretrained(pt_save_directory)When you are ready to use the model again, reload it with PreTrainedModel.from_pretrained():
pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")Github Issues
‘_datasets_server’ from ‘datasets.utils’
source link: https://github.com/modelscope/modelscope/issues/836
安装 datasets:
$ pip install datasets==2.18.0更多内容
缓存设置
源教程地址: https://huggingface.co/docs/transformers/installation#cache-setup .
Pretrained models are downloaded and locally cached at: ~/.cache/huggingface/hub. This is the default directory given by the shell environment variable TRANSFORMERS_CACHE. On Windows, the default directory is given by C:\Users\username\.cache\huggingface\hub. You can change the shell environment variables shown below - in order of priority - to specify a different cache directory:
- Shell environment variable (default):
HUGGINGFACE_HUB_CACHEorTRANSFORMERS_CACHE. - Shell environment variable:
HF_HOME. - Shell environment variable:
XDG_CACHE_HOME+/huggingface.
离线使用
源教程地址: https://huggingface.co/docs/transformers/installation#fetch-models-and-tokenizers-to-use-offline .
Another option for using 🤗 Transformers offline is to download the files ahead of time, and then point to their local path when you need to use them offline. There are three ways to do this:
- Download a file through the user interface on the
Model Hubby clicking on the↓icon.
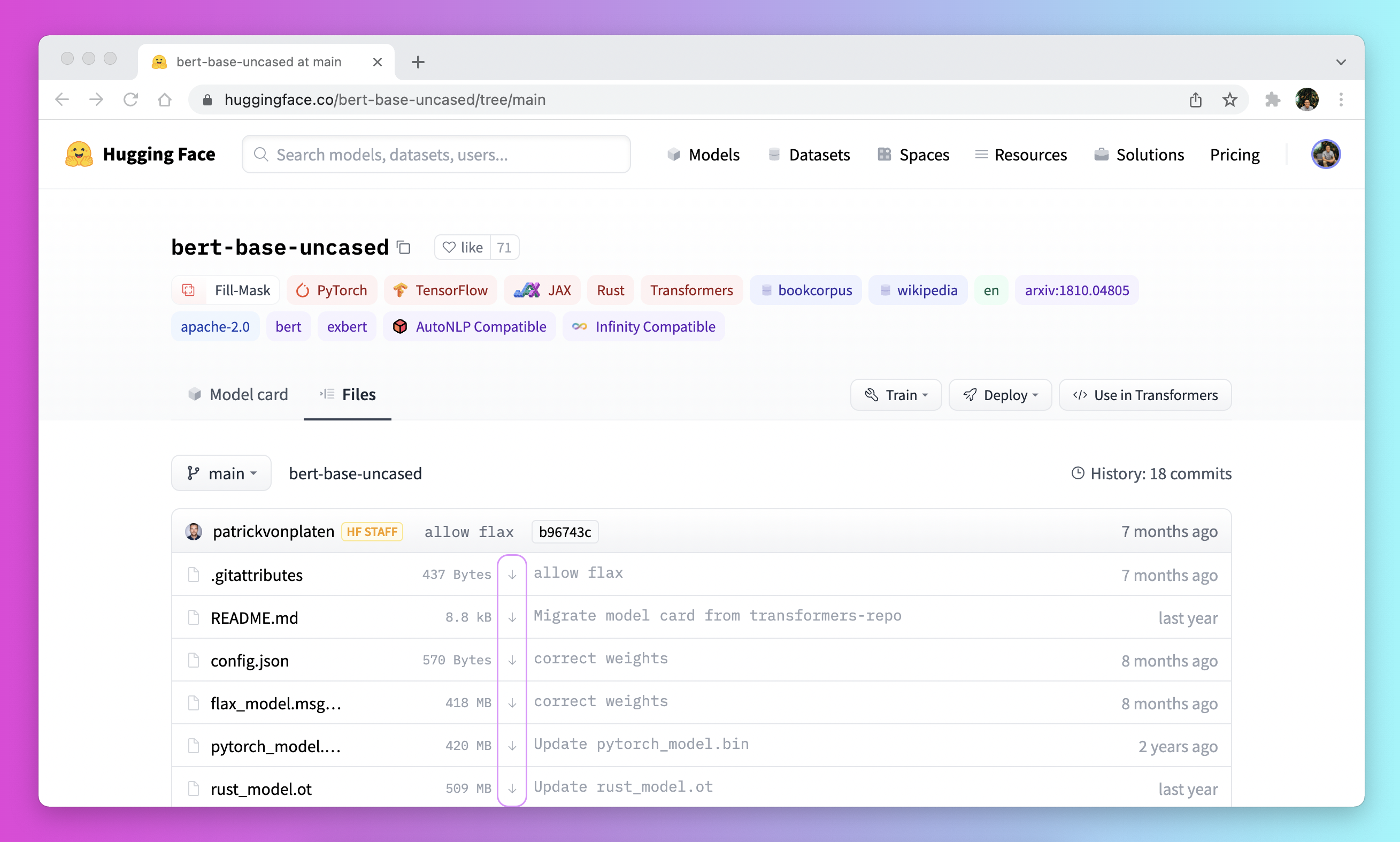
Use the
PreTrainedModel.from_pretrained()andPreTrainedModel.save_pretrained()workflow:Download your files ahead of time with
PreTrainedModel.from_pretrained():from transformers import AutoTokenizer, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B") model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")Save your files to a specified directory with
PreTrainedModel.save_pretrained():tokenizer.save_pretrained("./your/path/bigscience_t0") model.save_pretrained("./your/path/bigscience_t0")Now when you’re offline, reload your files with
PreTrainedModel.from_pretrained()from the specified directory:tokenizer = AutoTokenizer.from_pretrained("./your/path/bigscience_t0") model = AutoModel.from_pretrained("./your/path/bigscience_t0")
Programmatically download files with the
huggingface_hublibrary:Install the
huggingface_hublibrary in your virtual environment:python -m pip install huggingface_hubUse the
hf_hub_downloadfunction to download a file to a specific path. For example, the following command downloads theconfig.jsonfile from theT0model to your desired path:from huggingface_hub import hf_hub_download hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./your/path/bigscience_t0")
Once your file is downloaded and locally cached, specify it’s local path to load and use it:
from transformers import AutoConfig
config = AutoConfig.from_pretrained("./your/path/bigscience_t0/config.json")See the How to download files from the Hub section for more details on downloading files stored on the Hub.
结语
第七十九篇博文写完,开心!!!!
今天,也是充满希望的一天。



