T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems (NIPS 26), 2013.
X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS)., 2010.
A. Bordes, J. Weston, R. Collobert, and Y. Bengio. Learning structured embeddings of knowledge bases. In Proceedings of the 25th Annual Conference on Artificial Intelligence (AAAI), 2011.
R. Socher, D. Chen, C. D. Manning, and A. Y. Ng. Learning new facts from knowledge bases with neural tensor networks and semantic word vectors. In Advances in Neural Information Processing Systems (NIPS 26), 2013.
M. Nickel, V. Tresp, and H.-P. Kriegel. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on Machine Learning (ICML), 2011.
R. Jenatton, N. Le Roux, A. Bordes, G. Obozinski, et al. A latent factor model for highly multi-relational data. In Advances in Neural Information Processing Systems (NIPS 25), 2012.
A. Bordes, X. Glorot, J. Weston, and Y. Bengio. A semantic matching energy function for learning with multi-relational data. Machine Learning, 2013.
J. Weston, A. Bordes, O. Yakhnenko, and N. Usunier. Connecting language and knowledge bases with embedding models for relation extraction. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2013.
Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, Xuan Zhu. Learning entity and relation embeddings for knowledge graph completion. The 29th AAAI Conference on Artificial Intelligence, 2015.
负三元组 (corrupted triplets) 集合是根据上面的公式构造的, 是将训练集三元组中的 head 或者 tail 实体用随机的实体替换得到的 (head 和 tail 不同时替换). 损失函数会使训练集中的三元组的能量比负三元组低. 实体作为三元组的 head 和 tail 时的嵌入向量相同.
优化方法是随机梯度下降 (SGD), 并且使用 L2−norm 将实体和关系的嵌入向量限制为 1 (it prevents the training process to trivially minimize L by artificially increasing entity embeddings norms.1).
Wordnet: This KB is designed to produce an intuitively usable dictionary and thesaurus, and support automatic text analysis. Its entities (termed synsets) correspond to word senses, and relationships define lexical relations between them. We considered the data version used in 8, which we denote WN in the following. Examples of triplets are (_score_NN_1, _hypernym, _evaluation_NN_1) or (_score_NN_2, _has_part, _musical_notation_NN_1). WN is composed of senses, its entities are denoted by the concatenation of a word, its part-of-speech tag and a digit indicating which sense it refers to i.e. _score_NN_1 encodes the first meaning of the noun “score”.
Freebase: Freebase is a huge and growing KB of general facts; there are currently around 1.2 billion triplets and more than 80 million entities. We created two data sets with Freebase.
Unstructured: a version of TransE which considers the data as mono-relational and sets all translations to 0.
RESCAL: the collective matrix factorization model.
SE: energy-based models.
SME(linear)/SME(bilinear): energy-based models.
LFM: energy-based models.
基线模型的额外信息
RESCAL is trained via an alternating least-square method, whereas the others are trained by stochastic gradient descent, like TransE.
SME(linear), SME(bilinear), LFM and TransE have about the same number of parameters as Unstructured for low dimensional embeddings, the other algorithms SE and RESCAL, which learn at least one k × k matrix for each relationship rapidly need to learn many parameters.
RESCAL needs about 87 times more parameters on FB15k because it requires a much larger embedding space than other models to achieve good performance.
Implementation
TransE 超参数选择
For experiments with TransE, we selected the learning rate λ for the stochastic gradient descent among {0.001, 0.01, 0.1}, the margin γ among {1, 2, 10} and the latent dimension k among {20, 50} on the validation set of each data set.
The dissimilarity measured was set either to the L1 or L2 distance according to validation performance as well.
As expected, the filtered setting provides lower mean ranks and higherhits@10, which we believe are a clearer evaluation of the performance of the methods in link prediction.
The trends between raw and filtered are the same.
TransE, outperforms all counterparts on all metrics, usually with a wide margin.
The good performance of TransE is due to an appropriate design of the model according to the data, but also to its relative simplicity. This means that it can be optimized efficiently with stochastic gradient.
SE is more expressive than our proposal. However, its complexity may make it quite hard to learn, resulting in worse performance.
TransE is indeed less subject to underfitting and that this could explain its better performances.
基线模型详细的总体实验结果
SME(bilinear) and LFM suffer from the same training issue: we never managed to train them well enough so that they could exploit their full capabilities.
The poor results of LFM might also be explained by our evaluation setting, based on ranking entities, whereas LFM was originally proposed to predict relationships.
RESCAL can achieve quite good hits@10 on FB15k but yields poor mean ranks, especially on WN, even when we used large latent dimensions (2, 000 on Wordnet).
The impact of the translation term is huge.
Unstructured simply clusters all entities cooccurring together, independent of the relationships involved, and hence can only make guesses of which entities are related.
On FB1M, the mean ranks of TransE and Unstructured are almost similar, but TransE places 10 times more predictions in the top 10.
We classified the relationships into these four classes by computing, for each relationshipℓ, the averaged number of headsh (respect. tails t) appearing in the FB15k data set, given a pair (ℓ,t) (respect. a pair (h,ℓ)). If this average number was below 1.5 then the argument was labeled as 1 and MANY otherwise. For example, a relationship having an average of 1.2 head per tail and of 3.2 tails per head was classified as 1-to-Many.
Adding the translation term (i.e. upgrading Unstructured into TransE) brings the ability to move in the embeddings space, from one entity cluster to another by following relationships.
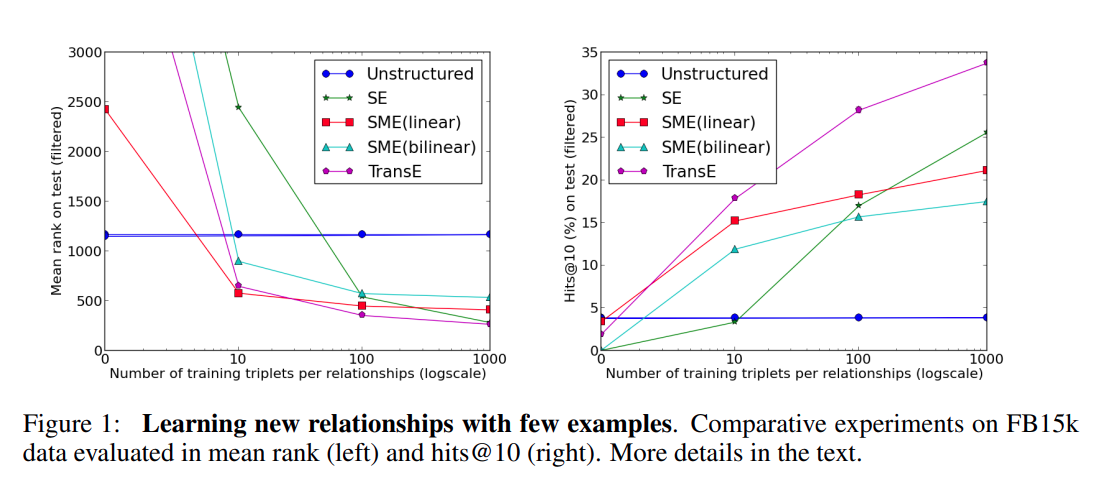
Learning to predict new relationships with few examples
实验细节
Using FB15k, we wanted to test how well methods could generalize to new facts by checking how fast they were learning new relationships.
To that end, we randomly selected 40 relationships and split the data into two sets: a set (named FB15k-40rel) containing all triplets with these 40 relationships and another set (FB15k-rest) containing the rest. We made sure that both sets contained all entities.
FB15k-rest has then been split into a training set of 353,788 triplets and a validation set of 53,266, and FB15k-40rel into a training set of 40,000 triplets (1,000 for each relationship) and a test set of 45,159.
Using these data sets, we conducted the following experiment: (1) models were trained and selected using FB15k-rest training and validation sets, (2) they were subsequently trained on the training set FB15k-40rel but only to learn the parameters related to the fresh 40 relationships, (3) they were evaluated in link prediction on the test set of FB15k-40rel (containing only relationships unseen during phase (1)).
We repeated this procedure while using 0, 10, 100 and 1000 examples of each relationship in phase (2).
实验结果
The performance of Unstructured is the best when no example of the unknown relationship is provided, because it does not use this information to predict. But, of course, this performance does not improve while providing labeled examples.
TransE is the fastest method to learn: with only 10 examples of a new relationship, the hits@10 is already 18% and it improves monotonically with the number of provided samples.
We believe the simplicity of the TransE model makes it able to generalize well, without having to modify any of the already trained embeddings.
We proposed a new approach to learn embeddings of KBs, focusing on the minimal parametrization of the model to primarily represent hierarchical relationships. We showed that it works very well compared to competing methods on two different knowledge bases, and is also a highly scalable model, whereby we applied it to a very large-scale chunk of Freebase data. Although it remains unclear to us if all relationship types can be modeled adequately by our approach, by breaking down the evaluation into categories (1-to-1, 1-to-Many, . . . ) it appears to be performing well compared to other approaches across all settings.
Future work could analyze this model further, and also concentrates on exploiting it in more tasks, in particular, applications such as learning word representations inspired by 2. Combining KBs with text as in 8 is another important direction where our approach could prove useful. Hence, we recently fruitfully inserted TransE into a framework for relation extraction from text 10.
################################################## # 创建 type_constrain.txt # type_constrain.txt: 类型约束文件, 第一行是关系的个数 # 下面的行是每个关系的类型限制 (训练集、验证集、测试集中每个关系存在的 head 和 tail 的类型) # 每个关系有两行: # 第一行:`id of relation` `Number of head types` `head1` `head2` ... # 第二行: `id of relation` `number of tail types` `tail1` `tail2` ... # # For example, the relation with id 1200 has 4 types of head entities, which are 3123, 1034, 58 and 5733 # The relation with id 1200 has 4 types of tail entities, which are 12123, 4388, 11087 and 11088 # 1200 4 3123 1034 58 5733 # 1200 4 12123 4388 11087 11088 ##################################################
f = open("../data/FB15K/type_constrain.txt", "w") f.write("%d\n"%(len(rel_lef))) for i in rel_lef: f.write("%s\t%d"%(i, len(rel_lef[i]))) for j in rel_lef[i]: f.write("\t%s"%(j)) f.write("\n") f.write("%s\t%d"%(i, len(rel_rig[i]))) for j in rel_rig[i]: f.write("\t%s"%(j)) f.write("\n") f.close() print("\n../data/FB15K/type_constrain.txt 创建成功.")
INT bern_flag = 1; INT load_binary_flag = 0; INT out_binary_flag = 0; INT dimension = 50; REAL alpha = 0.01; REAL margin = 1.0; INT nbatches = 1; INT epochs = 1000; INT threads = 32;
// 三元组: (head, label, tail) // h: head // r: label or relationship // t: tail // a relationship of name label between the entities head and tail structTriple { INT h, r, t; };
// 为第 id[0, threads) 线程返回取值为 [0, x) 的伪随机数 INT rand_max(INT id, INT x){ INT res = randd(id) % x; while (res < 0) res += x; return res; }
// 返回取值为 [min, max) 的伪随机数 REAL rand(REAL min, REAL max){ return min + (max - min) * rand() / (RAND_MAX + 1.0); }
// 正态分布函数,X ~ N (miu, sigma) REAL normal(REAL x, REAL miu, REAL sigma){ return1.0 / sqrt(2 * pi) / sigma * exp(-1 * (x-miu) * (x-miu) / (2 * sigma * sigma)); }
// 从正态(高斯)分布中抽取随机样本,取值为 [min, max) 的伪随机数 REAL randn(REAL miu, REAL sigma, REAL min, REAL max){ REAL x, y, d_scope; do { x = rand(min, max); y = normal(x, miu, sigma); d_scope = rand(0.0, normal(miu, miu, sigma)); } while (d_scope > y); return x; }
// 最大范数正则化函数: 如果输入向量的 L2 范数 > 1, 将输入向量的压缩, 使的其 L2 范数 = 1 // 可以参考: https://tensorflow.google.cn/api_docs/python/tf/keras/constraints/MaxNorm /* @keras_export("keras.constraints.MaxNorm", "keras.constraints.max_norm") class MaxNorm(Constraint): """MaxNorm weight constraint. Constrains the weights incident to each hidden unit to have a norm less than or equal to a desired value. Also available via the shortcut function `tf.keras.constraints.max_norm`. Args: max_value: the maximum norm value for the incoming weights. axis: integer, axis along which to calculate weight norms. For instance, in a `Dense` layer the weight matrix has shape `(input_dim, output_dim)`, set `axis` to `0` to constrain each weight vector of length `(input_dim,)`. In a `Conv2D` layer with `data_format="channels_last"`, the weight tensor has shape `(rows, cols, input_depth, output_depth)`, set `axis` to `[0, 1, 2]` to constrain the weights of each filter tensor of size `(rows, cols, input_depth)`. """ def __init__(self, max_value=2, axis=0): self.max_value = max_value self.axis = axis @doc_controls.do_not_generate_docs def __call__(self, w): norms = backend.sqrt( tf.reduce_sum(tf.square(w), axis=self.axis, keepdims=True) ) desired = backend.clip(norms, 0, self.max_value) return w * (desired / (backend.epsilon() + norms)) @doc_controls.do_not_generate_docs def get_config(self): return {"max_value": self.max_value, "axis": self.axis} */ voidnorm(REAL * vec){ REAL x = 0; for (INT i = 0; i < dimension; i++) x += (*(vec + i)) * (*(vec + i)); x = sqrt(x); if (x > 1) for (INT i = 0; i < dimension; i++) *(vec + i) /= x; }
// 输出预训练实体嵌入 for (INT i = 0; i < entity_total; i++) { INT last = i * dimension; for (INT j = 0; j < dimension; j++) fprintf(f1, "%.6f\t", entity_vec[last + j] ); fprintf(f1,"\n"); } printf("%s", ("\n输出预训练实体嵌入 (" + out_path + "entity2vec" + note + ".vec" + ") 成功.\n").c_str());
// 输出预训练关系嵌入 for (INT i = 0; i < relation_total; i++) { INT last = dimension * i; for (INT j = 0; j < dimension; j++) fprintf(f2, "%.6f\t", relation_vec[last + j]); fprintf(f2,"\n"); } printf("%s", ("输出预训练关系嵌入 (" + out_path + "relation2vec" + note + ".vec" + ") 成功.\n").c_str());
fclose(f1); fclose(f2); }
// ################################################## // Main function // ##################################################
// 寻找特定参数的位置 INT arg_pos(char *str, INT argc, char **argv){ INT a; for (a = 1; a < argc; a++) if (!strcmp(str, argv[a])) { if (a == argc - 1) { printf("Argument missing for %s\n", str); exit(1); } return a; } return-1; }
// optional arguments: // -bern [0/1] [1] 使用 bern 算法进行负采样,默认值为 [1] // -load-binary [0/1] [1] 以二进制形式加载预训练嵌入,默认值为 [0] // -out-binary [0/1] [1] 以二进制形式输出嵌入,默认值为 [0] // -size SIZE 实体和关系嵌入维度,默认值为 [50] // -alpha ALPHA 学习率,默认值为 0.01 // -margin MARGIN margin in max-margin loss for pairwise training,默认值为 1.0 // -nbatches NBATCHES number of batches for each epoch. if unspecified, nbatches will default to 1 // -epochs EPOCHS number of epochs. if unspecified, epochs will default to 1000 // -threads THREAD number of worker threads. if unspecified, threads will default to 32 // -input INPUT folder of training data. if unspecified, in_path will default to "../data/FB15K/" // -output OUTPUT folder of outputing results. if unspecified, out_path will default to "./build/" // -load LOAD folder of pretrained data. if unspecified, load_path will default to "" // -note NOTE information you want to add to the filename. if unspecified, note will default to "" // ##################################################
// 三元组: (head, label, tail) // h: head // r: label or relationship // t: tail // label(head-tail, relationship type): // 1: 1-1 // 2: 1-n // 3: n-1 // 4: n-n // a relationship of name label between the entities head and tail structTriple { INT h, r, t; INT label; };
// head_type: 存储各个关系的 head 类型, 各个关系的 head 类型独立地以升序排列 // tail_type: 存储各个关系的 tail 类型, 各个关系的 tail 类型独立地以升序排列 INT head_type[1000000]; INT tail_type[1000000];
// head_left: 记录各个关系的 head 类型在 head_type 中第一次出现的位置 // head_right: 记录各个关系的 head 类型在 head_type 中最后一次出现的后一个位置 // tail_left: 记录各个关系的 tail 类型在 tail_type 中第一次出现的位置 // tail_right: 记录各个关系的 tail 类型在 tail_type 中最后一次出现的后一个位置 INT head_left[10000]; INT head_right[10000]; INT tail_left[10000]; INT tail_right[10000];
// triple_list 用 head 排序 std::sort(triple_list, triple_list + triple_total, cmp_head());
// type_constrain.txt: 类型约束文件, 第一行是关系的个数 // 下面的行是每个关系的类型限制 (训练集、验证集、测试集中每个关系存在的 head 和 tail 的类型) // 每个关系有两行: // 第一行:`id of relation` `Number of head types` `head1` `head2` ... // 第二行: `id of relation` `number of tail types` `tail1` `tail2` ... // // For example, the relation with id 1200 has 4 types of head entities, which are 3123, 1034, 58 and 5733 // The relation with id 1200 has 4 types of tail entities, which are 12123, 4388, 11087 and 11088 // 1200 4 3123 1034 58 5733 // 1200 4 12123 4388 11087 11088 INT total_left = 0; INT total_right = 0; FILE* f_type = fopen((in_path + "type_constrain.txt").c_str(), "r"); tmp = fscanf(f_type, "%d", &relation_total); for (INT i = 0; i < relation_total; i++) { INT rel, tot; tmp = fscanf(f_type, "%d%d", &rel, &tot); head_left[rel] = total_left; for (INT j = 0; j < tot; j++) { tmp = fscanf(f_type, "%d", &head_type[total_left]); total_left++; } head_right[rel] = total_left; std::sort(head_type + head_left[rel], head_type + head_right[rel]);
// ################################################## // Main function // ##################################################
// 寻找特定参数的位置 INT arg_pos(char *str, INT argc, char **argv){ INT a; for (a = 1; a < argc; a++) if (!strcmp(str, argv[a])) { if (a == argc - 1) { printf("Argument missing for %s\n", str); exit(1); } return a; } return-1; }
// optional arguments: // -load-binary [0/1] [1] 以二进制形式加载预训练嵌入,默认值为 [0] // -size SIZE 实体和关系嵌入维度,默认值为 [50] // -threads THREAD number of worker threads. if unspecified, threads will default to 32 // -input INPUT folder of training data. if unspecified, in_path will default to "../data/FB15K/" // -load LOAD folder of pretrained data. if unspecified, load_path will default to "./build/" // -note NOTE information you want to add to the filename. if unspecified, note will default to "" // ##################################################
$ ls data papers README.md TransE $ cd TransE/ $ ls clean.sh data_preprocessing.py run.sh test_transE.cpp transE.cpp $ bash run.sh ##################################################
optional arguments: -bern [0/1] [1] 使用 bern 算法进行负采样,默认值为 [1] -load-binary [0/1] [1] 以二进制形式加载预训练嵌入,默认值为 [0] -out-binary [0/1] [1] 以二进制形式输出嵌入,默认值为 [0] -size SIZE 实体和关系嵌入维度,默认值为 [50] -alpha ALPHA 学习率,默认值为 0.01 -margin MARGIN margin in max-margin loss for pairwise training,默认值为 1.0 -nbatches NBATCHES number of batches for each epoch. if unspecified, nbatches will default to 1 -epochs EPOCHS number of epochs. if unspecified, epochs will default to 1000 -threads THREAD number of worker threads. if unspecified, threads will default to 32 -input INPUT folder of training data. if unspecified, in_path will default to "../data/FB15K/" -output OUTPUT folder of outputing results. if unspecified, out_path will default to "./build/" -load LOAD folder of pretrained data. if unspecified, load_path will default to "" -note NOTE information you want to add to the filename. if unspecified, note will default to ""
optional arguments: -load-binary [0/1] [1] 以二进制形式加载预训练嵌入,默认值为 [0] -size SIZE 实体和关系嵌入维度,默认值为 [50] -threads THREAD number of worker threads. if unspecified, threads will default to 32 -input INPUT folder of training data. if unspecified, in_path will default to "../data/FB15K/" -load LOAD folder of pretrained data. if unspecified, load_path will default to "./build/" -note NOTE information you want to add to the filename. if unspecified, note will default to ""


 wechat
wechat alipay
alipay.png)










